L2/01-445
(updating L2/01-390)
| Re: | Explicit Properties for Special Casing & Titlecase |
| To: | UTC |
| From: | Mark Davis, Markus Scherer |
| Date: | 2001-11-05 |
In SpecialCasing.txt a specification is used to determine characters that should be ignored with determining whether a letter is final or not. This is described in the comments of the file as:
# - An ignorable sequence is a sequence of *zero* or more characters from
# the set {HYPHEN, SOFT HYPHEN, general category = Mn}.
This same specification can be used for default titlecasing of strings, to ignore characters that should not have an effect in determining which letters are initial. However, this should be an explicit property in the UCD, rather than just in the documentation of the data file.
Similarly, the TYPE_i value listed there should have an explicit list.
The following new properties are proposed for addition to the next version of Unicode.
Note:
0027 ; Other_Case_Ignorable # Po APOSTROPHE 00AD ; Other_Case_Ignorable # Pd SOFT HYPHEN 2019 ; Other_Case_Ignorable # Pf RIGHT SINGLE QUOTATION MARK # Total code points: 3
# Derived Property: Special_Dotted # Generated from: characters whose canonical decompositions # end with a combining character sequence that # - starts with i or j # - has no combining marks above # - has no combining marks with zero canonical combining class 0069..006A ; Special_Dotted # L& [2] LATIN SMALL LETTER I..LATIN SMALL LETTER J 012F ; Special_Dotted # L& LATIN SMALL LETTER I WITH OGONEK 1E2D ; Special_Dotted # L& LATIN SMALL LETTER I WITH TILDE BELOW 1ECB ; Special_Dotted # L& LATIN SMALL LETTER I WITH DOT BELOW # Total code points: 5 # ================== # Derived Property: Case_Ignorable # Generated from: Other_Case_Ignorable + Lm + Mn + Me + Cf 0027 ; Case_Ignorable # Po APOSTROPHE 00AD ; Case_Ignorable # Pd SOFT HYPHEN
...
E0001 ; Case_Ignorable # Cf LANGUAGE TAG E0020..E007F ; Case_Ignorable # Cf [96] TAG SPACE..CANCEL TAG # Total code points: 657
In addition, there are some typos/problems in SpecialCasing.txt that need to be fixed.
# - A cased letter is any character with general category = Ll or Lo or Lt
Should be Lu, not Lo.
Add a clarification to the header:
# The context is always the context of the characters in the original string, # NOT in the resulting string.
For Turkish, we have the following in the file. It is intended to make sure that I and I+dot work the same:
# Remove spurious dot above small i's when lowercasing, if there are no more accents above: 0307; ; 0307; 0307; tr AFTER_i NOT_MORE_ABOVE # COMBINING DOT ABOVE
It is not sufficient, since (a) the context should be after an uppercase I, not lowercase, and (b) the previous I would already have been transformed into a dotless lowercase, which is incorrect. In addition, it is more general (as per Kent's document) to handle lowercasing of the dot_above as locale-independent.
To fix these issues:
# AFTER_I: The last preceding base character was an uppercase I, and # no combining character class 230 (above) has intervened. # BEFORE_DOT: The character is followed by combining dot above (U+0307). # Any sequence of characters with a combining class that is # neither 0 nor 230 may intervene between the current character # and the combining dot above.
(Also, add a regular-expression formulation to each condition for clarity.)
# Remove spurious dot above small i's when lowercasing, if there are no more accents above: 0307; ; 0307; 0307; tr AFTER_i NOT_MORE_ABOVE # COMBINING DOT ABOVE 0307; ; 0307; 0307; az AFTER_i NOT_MORE_ABOVE # COMBINING DOT ABOVE # Fix case pairs 0049; 0131; 0049; 0049; tr; # LATIN CAPITAL LETTER I 0069; 0069; 0130; 0130; tr; # LATIN SMALL LETTER I 0049; 0131; 0049; 0049; az; # LATIN CAPITAL LETTER I 0069; 0069; 0130; 0130; az; # LATIN SMALL LETTER I
# When lowercasing, remove dot_ above in the sequence I + dot_ above, which will turn into i. # This matches the behavior of the canonically equivalent I-dot_above 0307; ; 0307; 0307; AFTER_I # COMBINING DOT ABOVE
# When lowercasing, unless an I is before a dot_above, it turns into a dotless i. 0049; 0131; 0049; 0049; tr NOT_BEFORE_DOT; # LATIN CAPITAL LETTER I 0049; 0131; 0049; 0049; az NOT_BEFORE_DOT; # LATIN CAPITAL LETTER I # When uppercasing, i turns into a dotted capital I 0069; 0069; 0130; 0130; tr; # LATIN SMALL LETTER I 0069; 0069; 0130; 0130; az; # LATIN SMALL LETTER I
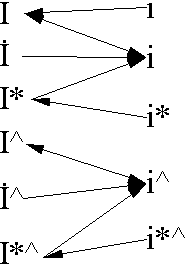
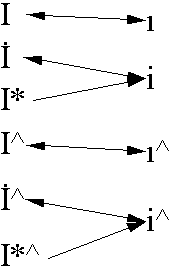
The end result will be the following (where * represents a combining dot above, and ^ represents any other above accent). The important formal characteristic is that dotted-I and I + dot always produce the same results.
| Normal | tr & az |
|---|---|
|
|
|
The mappings in SpecialCasing predate NFC. Certain of the mappings are not in NFC format. While not formally incorrect, it would be better if these were changed to NFC. The list is the following (the ## lines are the old values)
## 0390; 0390; 0399 0308 0301; 0399 0308 0301; # GREEK SMALL LETTER IOTA WITH
DIALYTIKA AND TONOS
0390; 0390; 03AA 0301; 03AA 0301; # GREEK SMALL LETTER IOTA WITH DIALYTIKA AND
TONOS
## 03B0; 03B0; 03A5 0308 0301; 03A5 0308 0301; # GREEK SMALL LETTER UPSILON WITH
DIALYTIKA AND TONOS
03B0; 03B0; 03AB 0301; 03AB 0301; # GREEK SMALL LETTER UPSILON WITH DIALYTIKA
AND TONOS
## 1FB7; 1FB7; 0391 0342 0345; 0391 0342 0399; # GREEK SMALL LETTER ALPHA WITH
PERISPOMENI AND YPOGEGRAMMENI
1FB7; 1FB7; 1FBC 0342; 0391 0342 0399; # GREEK SMALL LETTER ALPHA WITH
PERISPOMENI AND YPOGEGRAMMENI
## 1FC7; 1FC7; 0397 0342 0345; 0397 0342 0399; # GREEK SMALL LETTER ETA WITH
PERISPOMENI AND YPOGEGRAMMENI
1FC7; 1FC7; 1FCC 0342; 0397 0342 0399; # GREEK SMALL LETTER ETA WITH PERISPOMENI
AND YPOGEGRAMMENI
## 1FD2; 1FD2; 0399 0308 0300; 0399 0308 0300; # GREEK SMALL LETTER IOTA WITH
DIALYTIKA AND VARIA
1FD2; 1FD2; 03AA 0300; 03AA 0300; # GREEK SMALL LETTER IOTA WITH DIALYTIKA AND
VARIA
## 1FD7; 1FD7; 0399 0308 0342; 0399 0308 0342; # GREEK SMALL LETTER IOTA WITH
DIALYTIKA AND PERISPOMENI
1FD7; 1FD7; 03AA 0342; 03AA 0342; # GREEK SMALL LETTER IOTA WITH DIALYTIKA AND
PERISPOMENI
## 1FE2; 1FE2; 03A5 0308 0300; 03A5 0308 0300; # GREEK SMALL LETTER UPSILON WITH
DIALYTIKA AND VARIA
1FE2; 1FE2; 03AB 0300; 03AB 0300; # GREEK SMALL LETTER UPSILON WITH DIALYTIKA
AND VARIA
## 1FE7; 1FE7; 03A5 0308 0342; 03A5 0308 0342; # GREEK SMALL LETTER UPSILON WITH
DIALYTIKA AND PERISPOMENI
1FE7; 1FE7; 03AB 0342; 03AB 0342; # GREEK SMALL LETTER UPSILON WITH DIALYTIKA
AND PERISPOMENI
## 1FF7; 1FF7; 03A9 0342 0345; 03A9 0342 0399; # GREEK SMALL LETTER OMEGA WITH
PERISPOMENI AND YPOGEGRAMMENI
1FF7; 1FF7; 1FFC 0342; 03A9 0342 0399; # GREEK SMALL LETTER OMEGA WITH
PERISPOMENI AND YPOGEGRAMMENI