| Revision | 0.2 |
| Authors | Asmus Freytag |
| Date | May 19, 1998 |
| This Version | http://www.unicode.org/unicode/reports/dtr11-02.html |
| Previous Version | -none- |
| Latest Version | http://www.unicode.org/unicode/reports/dtr11.html |
Summary
This report presents the specifications of a new property for Unicode characters.
Status of this document
This draft is published for public review . Previous versions of this document have been considered by the Unicode Technical Committee, and it has had preliminary approval as a Draft Unicode Technical Report. The Unicode Technical Committee may approve, reject, or further amend this document before it becomes an approved Unicdoe Technical Report. This document does not, at this time, imply any endorsement by the Consortium's staff or member organizations. Please mail comments to the
author.In mixed-width, East Asian, legacy encodings there is a concept of an inherent width of a character. For a fixed pitch font, this width translates to a display width of either one half or a whole unit width. A common name for this unit width is "Em". It is customarily the height of the letter 'M', but since in East Asian fonts the standard character cell is square, it is the same as the unit width.
NOTE:
the average character width for proportionally spaced Latin fonts is different, i.e. 1/3 em for Courier.Layout and line breaking (to cite only two examples) in an East Asian context show systematic variations depending on the value of the East-Asian Width property (even for non-fixed pitch fonts). Further, the same information is useful in creating correct transcoding tables for East Asian character sets.
The East Asian Width property provides a useful concept for implementations that
By convention, 1/2 Em wide characters of East Asian legacy encodings are called "half-width" (or hankaku characters in Japanese), the others are called correspondingly "full-width" (or zenkaku) characters. Legacy encodings often use a single byte for the half-width characters and two bytes for the full-width characters. In the Unicode Standard, no such distinction is made.
Some character blocks in the compatibility zone contain characters that are explicitly marked "half-width" and "full-width" in their character name but for all other characters the width property must be implicitly derived. Some characters behave differently in East Asian context than in non-East Asian content. Their default widht property is considered ambiguous and needs to be resolved into an actual width property based on context.
This technical report assigns to each Unicode character one of the five values Ambiguous, Full Width, Half Width, Narrow, and Wide (defined below) as its default width property. Depending on context, hese five default properties resolve into only two property values narrow and wide.
East Asian Width
- in the context of interoperating with East Asian legacy character encodings and implementing East Asian typography, character width is an abstract concept. It can take on two values, narrow and wide. The actual display width of a glyph is given by the font. An important class of fixed width legacy fonts contains glyphs of just two widths with the wider glyphs twice as wide as the narrower glyph.East Asian Wide (W) -
There are wide characters that are defined as full-width and also wide characters that are implicitly wide (such as the Unified Han Ideographs or Squared Katakana Symbols) because they occur only in the context of East Asian typography where they are wide characters.East Asian FullWidth (FW) -
East Asian Wide characters that are defined as full width and therefore are compatibility equivalents of implicitly narrow but unmarked characters elsewhere in the Unicode Standard. FW characters form a proper subset of W characters.East Asian Narrow (N) -
There are narrow characters that are defined as half-width and also characters that are half-width by implication because they have full-width clones (all of ASCII is an example).East Asian Half-width (HW) -
Narrow characters that are defines as half-width and therefore are compatibility characters of implicitly wide, but unmarked characters elsewhere in the Unicode Standard. HW characters form a proper subset of N characters.Note:
Because half-width punctuation behaves in some important ways like ideographic punctuation, it is useful to distinguish characters defined as half-width from characters that are narrow by implication. Alternatively, it is useful to distinguish characters defined as half-width from general purpose characters that are narrow by implication where there are duplicate pairs (this is a smaller number). Since the latter cannot be trivially derived from the block names, it is what is proposed explicitly below.East Asian Ambiguous (A) -
Characters that occur in East Asian legacy character sets as wide characters, and as narrow characters in their own local or non-East Asian usage (Examples are the Greek and Cyrillic Alphabet found in East Asian character sets, but also some of the mathematical symbols). Ambiguous characters require context to resolve their width.Not East Asian (Neutral) -
All characters that neither occur in legacy East Asian character sets. By extension, they also do not occur in East Asian typography. (There is no traditional Japanese way of typesetting Devanagari, for example).
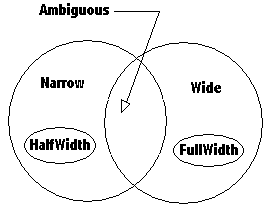
Figure 1: Venn diagram showing the set relations for the five properties.
When converting a DBCS mixed-width encoding to and from Unicode, the full-width characters in such a mixed-width encoding are mapped to the full-width compatibility characters in the FFxx block, whereas the corresponding half-width characters are mapped to ordinary Unicode characters (e.g. ASCII in U+0021..U+007E, plus a few other scattered characters).
In the context of interoperability with DBCS character encodings, that restricted set of Unicode characters in the General Scripts area can be construed as half-width, rather than full-width. (This applies only to the restricted set of characters which can be paired with the full-width compatibility characters.)
In the context of interoperability with DBCS character encodings, all other Unicode characters which are not explicitly marked as half-width can be construed as full-width.
In any other context, Unicode characters not explicitly marked as being either full-width or half-width compatibility forms should be construed as unmarked as to half-width versus full-width status.
Seen in this light, the "half-width" and "full-width" properties are not unitary character properties in the same sense as "space" or "combining" or "alphabetic". They are, instead, relational properties of a pair of characters, one of which is explicitly encoded as a half-width or full-width form for compatibility in mapping to DBCS mixed-width character encodings.
What is "full-width" by default today could in theory become "half-width" tomorrow by the introduction of another character on the SBCS part of a mixed-width code page somewhere, requiring the introduction of another full-width compatibility character to complete the mapping. Since the single byte part of mixed-width character sets is limited, there are not going to be many candidates and UTC and WG2 both will resist adding compatibility characters unless they are truly critical.
East Asian Width is an informative character property.
When interchanging data
When processing or displaying data
A - Ambiguous0000..001F 00A1 00A4 00A7..00A8 00AA 00AD 00AF..00B4 00B6..00BA 00BC..00BF 00C6 00D0 00D7..00D8 00DE..00E1 00E6 00E8..00EA 00EC..00ED 00F0 00F2..00F3 00F7..00FA 00FC 00FE 0101 0111 0113 011B 0126..0127 012B 0131..0133 0138 013F..0142 0144 0148..014B 014D 0152..0153 0166..0167 016B 01CE 01D0 01D2 01D4 01D6 01D8 01DA 01DC 0251 0261 02C7 02C9..02CB 02CD 02D0 02D8..02DB 02DD 0300..0361 0391..03A9 03B1..03C1 03C3..03C9 0401 0410..044F 0451 2010 2013..2016 2018..2019 201C..201D 2020..2021 2025..2027 2030 2032..2033 2035 203B 2074 207F 2081..2084 2103 2105 2109 2113 2116 2121..2122 2126 212B 2153..2154 215B..215E 2160..216B 2170..2179 2190..2199 21D2 21D4 2200 2202..2203 2207..2208 220B 220F 2211 2215 221A 221D..2220 2223 2225 2227..222C 222E 2234..2237 223C..223D 2248 224C 2252 2260..2261 2264..2267 226A..226B 226E..226F 2282..2283 2286..2287 2295 2299 22A5 22BF 2312 2460..24B5 24D0..24E9 2500..254B 2550..2574 2581..258F 2592..25A1 25A3..25A9 25B2..25B3 25B6..25B7 25BC..25BD 25C0..25C1 25C6..25C8 25CB 25CE..25D1 25E2..25E5 25EF 2605..2606 2609 260E..260F 261C 261E 2640 2642 2660..2661 2663..2665 2667..266A 266C..266D 266F H - Halfwidth 20A9 FF61..FF64 N - Narrow 0020..00A0 00A2..00A3 00A5..00A6 00A9 00AB..00AC 00AE 00B5 00BB 00C0..00C5 00C7..00CF 00D1..00D6 00D9..00DD 00E2..00E5 00E7 00EB 00EE..00EF 00F1 00F4..00F6 00FB 00FD 00FF..0100 0102..0110 0112 0114..011A 011C..0125 0128..012A 012C..0130 0134..0137 0139..013E 0143 0145..0147 014C 014E..0151 0154..0165 0168..016A 016C..01CD 01CF 01D1 01D3 01D5 01D7 01D9 01DB 01DD..0250 0252..0260 0262..02A8 02B0..02C6 02C8 02CC 02CE..02CF 02D1..02D7 02DC 02DE 02E0..02E9 0374..0390 03AA..03B0 03C2 03CA..03EF 0400 0402..040F 0450 0452..0486 0490..04F9 0531..0556 0559..055F 0561..0587 0589 0591..05F4 060C..06F9 0901..0970 0981..09FA 0A02..0A74 0A81..0AEF 0B01..0B70 0B82..0BF2 0C01..0C6F 0C82..0CEF 0D02..0D6F 0E01..0E5B 0E81..0EDD 0F00..0FB9 10A0..10F6 10FB 1E00..1EF9 1F00..1FFE 2000..200F 2011..2012 2017 201A..201B 201E..201F 2022..2024 2028..202E 2031 2034 2036..203A 203C..2046 206A..2070 2075..207E 2080 2085..208E 20A0..20A8 20AA..20AB 20D0..2102 2104 2106..2108 210A..2112 2114..2115 2117..2120 2123..2125 2127..212A 212C..2138 2155..215A 215F 216C..216F 217A..2182 219A..21D1 21D3 21D5..21EA 2201 2204..2206 2209..220A 220C..220E 2210 2212..2214 2216..2219 221B..221C 2221..2222 2224 2226 222D 222F..2233 2238..223B 223E..2247 2249..224B 224D..2251 2253..225F 2262..2263 2268..2269 226C..226D 2270..2281 2284..2285 2288..2294 2296..2298 229A..22A4 22A6..22BE 22C0..2311 2313..244A 24B6..24CF 24EA 254C..254F 2575..2580 2590..2591 25A2 25AA..25B1 25B4..25B5 25B8..25BB 25BE..25BF 25C2..25C5 25C9..25CA 25CC..25CD 25D2..25E1 25E6..25EE 2600..2604 2607..2608 260A..260D 2610..261B 261D 261F..263F 2641 2643..265F 2662 2666 266B 266E 2701..27BE 3105..312C FB00..FB06 FB13..FB17 FB1E..FDFB FE20..FE23 FE70..FEFC FEFF FF65..FFDC FFE8..FFEE FFFC..FFFD W - Wide 1100..11F9 3000..303F 3041..3094 3099..309E 30A1..30FE 3131..318E 3190..319F 3200..321C 3220..3243 3260..32B0 32C0..3376 337B..33DD 33E0..33FE 4E00..9FA5 AC00..D7A3 E000..E757 F900..FA2D F - FullWidth FE30..FE44 FE49..FE52 FE54..FE6B FF01..FF5E FFE0..FFE6 X - Unassigned 02A9..02AF 02DF 02EA..02FF 0362..0373 03F0..03FF 0487..048F 04FA..0530 0557..0558 0560 0588 058A..0590 05F5..060B 06FA..0900 0971..0980 09FB..0A01 0A75..0A80 0AF0..0B00 0B71..0B81 0BF3..0C00 0C70..0C81 0CF0..0D01 0D70..0E00 0E5C..0E80 0EDE..0EFF 0FBA..109F 10F7..10FA 10FC..10FF 11FA..1DFF 1EFA..1EFF 1FFF 202F 2047..2069 2071..2073 208F..209F 20AC..20CF 2139..2152 2183..218F 21EB..21FF 244B..245F 24EB..24FF 25F0..25FF 2670..2700 27BF..2FFF 3040 3095..3098 309F..30A0 30FF..3104 312D..3130 318F 31A0..31FF 321D..321F 3244..325F 32B1..32BF 3377..337A 33DE..33DF 33FF..4DFF 9FA6..ABFF D7A4..DFFF E758..F8FF FA2E..FAFF FB07..FB12 FB18..FB1D FDFC..FE1F FE24..FE2F FE45..FE48 FE53 FE6C..FE6F FEFD..FEFE FF00 FF5F..FF60 FFDD..FFDF FFE7 FFEF..FFFB
ISO 10646 is silent on the terms "half-width" and "full-width" except to say that the characters so named are provided for compatibility.
The Unicode Standard states (p. 6-130):
In the context of conversion to and from such mixed-width encodings, all characters in the General Scripts area [i.e. 0000-1FFF] should be construed as half-width (hankaku) characters.
This sentence, as it stands, is misleading in that it implies that everything in the range U+0000..U+1FFF is half-width.
All characters in the CJK Phonetics and Symbols area [i.e. 3000-33FF] and the Unified CJK Ideograph area [i.e. 4E00-9FFF], along with the characters in the CJK Compatibility Ideographs [i.e. F900-FAFF], CJK Compatibility Forms [i.e. FE30-FE4F], and Small Form Variants blocks [i.e. FE50-FE6F], should be construed as full-width (zenkaku) characters. Other Compatibility Area [i.e. F900-FFFF] characters outside of the current block should be construed as half-width characters. The characters of the Symbols Area are neutral regarding their width semantics.
It should clearly be noted that statements made in the Unicode Standard in Chapter 6 (Character Block Descriptions) do not have normative status. Chapters 3, 4, and 7 (Charts) have normative status. The rest of the book, including Chapter 6 is provided basically to give as much information as possible to help people understand and implement the characters correctly. But it is dangerous to make legalistic arguments based on the text of Chapter 6, since there is rather large leeway for the editors of the Unicode Standard to modify and augment such explanatory text as new issues arise or old ones require more clarification.
The intent of the existing paragraph is not to create a property but to account for the fact that there are full-width forms encoded in the ranges U+FF01..U+FF5E and U+FFE0..U+FFE6.
Michel Suignard provided extensive input into the analysis and source material for the detail assignments of these properties.
Part of this document draws on e-mail discussion contribution by Ken Whistler, heavily edited, so don't blame him.
Asmus Freytag wrote the document.
First draft technical report version. Extensive formatting to fit the template. Split Wide into Wide and FullWidth to capture the characters with explicit FullWidth characteristics.
Copyright © 1998-1998 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.
Unicode Home Page: http://www.unicode.org
Unicode Technical Reports: http://www.unicode.org/unicode/reports/techreports.html