| Version | 3 |
| Authors | Mark Davis (mark.davis@us.ibm.com) |
| Date | 2002-10-11 |
| This Version | http://www.unicode.org/reports/tr29/tr29-3.html |
| Previous Version | http://www.unicode.org/reports/tr29/tr29-2.html |
| Latest Version | http://www.unicode.org/reports/tr29 |
| Tracking Number | 3 |
This document describes guidelines for determining default boundaries between certain significant text elements: grapheme clusters (“user characters”), words, and sentences. For line-break boundaries, see UAX #14: Line Breaking Properties.
This document is a draft Unicode Technical Report. Publication does not imply endorsement by the Unicode Consortium. This is a draft document which may be updated, replaced, or superseded by other documents at any time. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
Note: The intention is for this document to become a UAX, once approved.
A list of current Unicode Technical Reports is found on [Reports]. For more information about versions of the Unicode Standard, see [Versions]. Please mail corrigenda and other comments to the author(s). The References provide related information that is useful in understanding this document.
Please mail corrigenda and other comments to the author(s).
This document describes guidelines for determining default boundaries between certain significant text elements: grapheme clusters (“user characters”), words, and sentences. It updates most of 5.15 Locating Text Element Boundaries, except for the line-break boundaries, which are covered in UAX #14: Line Breaking Properties.
A string of Unicode-encoded text often needs to be broken up into text elements programmatically. Common examples of text elements include what users think of as characters, words, lines (more precisely, where line breaks are allowed), and sentences. The precise determination of text elements may vary according to orthographic conventions for a given script or language. The goal of matching user perceptions cannot always be met exactly because the text alone does not always contain enough information to unambiguously decide boundaries. For example, the period (U+002E full stop) is used ambiguously, sometimes for end-of-sentence purposes, sometimes for abbreviations, and sometimes for numbers. In most cases, however, programmatic text boundaries can match user perceptions quite closely, or at least not surprise the user.Rather than concentrate on algorithmically searching for text elements themselves, a simpler and more useful computation looks instead at detecting the boundaries (or breaks) between those text elements. The determination of those boundaries is often critical to the performance of general software, so it is important to be able to make such a determination as quickly as possible.
The default boundary determination mechanism provides a straightforward and efficient way to determine some of the most significant boundaries in text: grapheme clusters (what end-users usually think of as characters), words, and sentences. (Line boundaries are to be found in UAX #14: Line Breaking Properties.)
Boundary determination builds upon the uniform character representation of the Unicode Standard, while handling the large number of characters and special features such as combining marks and conjoining jamo in an effective manner. As this mechanism lends itself to a completely data-driven implementation, it can be tailored to particular orthographic conventions or user preferences without recoding.
The large character set of the Unicode Standard and its representational power place requirements on both the specification of text element boundaries and the underlying implementation. The specification needs to allow for the designation of large sets of characters sharing the same characteristics (for example, uppercase letters), while the implementation must provide quick access and matches to those large sets. The mechanism also must handle special features of the Unicode Standard, such as combining or nonspacing marks and conjoining jamo.
A boundary specification defines boundary property values used in that specification, then lists the rules for boundaries in terms of those property values. The characters having those property values are specified as a list, where each element of the list is:
Each rule consists of a left side, a boundary symbol, and a right side. Either of the sides can be empty. The left and right sides use the boundary property values in regular expressions. For more information on regular expression syntax used, see UTR #18: Unicode Regular Expression Guidelines.
The boundary symbols are:
|
÷ |
Boundary (allow break here) |
| × | No Boundary (do not allow break here) |
| → | Treat whatever on the left side as if it were what is on the right side. |
An underscore (“_”) is used to indicate a space in examples.
As in other cases, these are a logical description of the processes: implementations can achieve the same results without using code or data that follows these rules step-by-step. In particular, many production-grade implementations will use a state-table approach. In that case, the performance does not depend on the complexity or number of rules. The only feature that does affect performance is the number of characters that may match after the boundary position in a rule that is matched.
Some additional constraints are reflected in the specification. These constraints make the implementation significantly simpler and more efficient and have not been found to be limitations for natural language use.
Editorial Note: The Unicode 3.0 text contained text including more constraints and other descriptions, but that text had fallen out of date, and does not apply to the default boundaries described in this document, nor to UAX #14: Line Breaking Properties.
Different issues are present with different types of boundaries, as the following discussion and examples should make clear.
This is informative material. There are many different ways to divide text elements corresponding to grapheme clusters, words and sentences, and the Unicode Standard and this document do not restrict the ways in which implementations can do this.
This specification is a default mechanism; more sophisticated engines can and should tailor it for particular locales or environments. For example, good Thai, Lao, Chinese, or Japanese word-break boundaries require the use of dictionary lookup, analogous to English hyphenation. An implementation therefore may need to provide means to override or subclass the default mechanism described in this document. Note that tailoring can either add boundary positions or remove boundary positions, compared to the default specified here.
To maintain canonical equivalence, all of the following specifications are defined on NFD text, as defined in UAX #15: Unicode Normalization Forms [Reports]. A boundary exists in non-NFD text just in case it would occur at the corresponding position in NFD text. However, this is only a logical specification; in practice implementations can avoid normalization and achieve the same results. For more information, see §6 Implementation Notes.
One or more Unicode characters may make up what the user thinks of as a character or basic unit of the language. To avoid ambiguity with the computer use of the term character, this is called a grapheme cluster. For example, “G” + acute-accent is a grapheme cluster: it is thought of as a single character by users, yet is actually represented by two Unicode code points. For more information on the ambiguity in the term character, see UTR #17: Character Encoding Model [Reports].
Grapheme clusters include, but are not limited to, combining character sequences such as (g + °), digraphs such as Slovak “ch”, and sequences with letter modifiers such as kw. Grapheme cluster boundaries are important for collation, regular-expressions, and counting “character” positions within text. Word boundaries, line boundaries and sentence boundaries do not occur within a grapheme cluster. In this section, the Unicode Standard provides a determination of where the default grapheme boundaries fall in a string of characters. This algorithm can be tailored for specific locales or other customizations, which is what is done in providing contracting characters in collation tailoring tables.
Note: In previous documentation, default grapheme clusters were previously referred to as “locale-independent graphemes”. The term cluster has been added to emphasize that the term grapheme as used differently in linguistics. For simplicity and to align with UTS #10: Unicode Collation Algorithm [Reports], the terms default and tailored are used in preference to locale-independent and locale-dependent, respectively.
As far as a user is concerned, the underlying representation of text is not important, but it is important that an editing interface present a uniform implementation of what the user thinks of as characters. Grapheme clusters commonly commonly behave as units in terms of mouse selection, arrow key movement, backspacing, and so on. When this is done, for example, and an accented character is represented by a combining character sequence, then using the right arrow key would skip from the start of the base character to the end of the last combining character.
However, in some cases editing a grapheme cluster element by element may be the preferred way. For example, a system might have backspace delete by code point, while the delete key may delete an entire cluster. Moreover, there is not a one-to-one relationship between grapheme clusters and keys on a keyboard. A single key on a keyboard may correspond to: a whole grapheme cluster, a part of a grapheme clusters, or a sequence of more than one grapheme clusters.
In those rare circumstances where end-users need character counts, the counts should correspond to the grapheme cluster boundaries.
The principal requirements for default grapheme cluster boundaries are the handling of combining marks and Hangul conjoining jamo. Boundaries may be further tailored for requirements of different languages, such as the addition of “ch” for Slovak, or Indic, Thai or Tibetan character clusters.
A default grapheme cluster normally begins with a base character. Exceptions are when a combining mark is at the start of text, or it is preceded by a control (or format) character. The boundary of a default grapheme cluster can be determined by just the adjacent characters. For the rules defining the default boundaries, see Table 1, Default Grapheme Cluster Boundaries below.
For more information on the composition of Hangul Syllables (with L, V, or T) see 3.11 Conjoining Jamo Behavior (revision) in UAX #28: Unicode Version 3.2 [U3.2].
[Editorial Note: the above reference will be changed to point to Unicode 4.0 once that is available.]
Degenerate Cases. As with other definitions in Chapter 5 and elsewhere, these definitions are designed to be simple to implement. They need to provide an algorithmic determination of the valid, default grapheme clusters, and exclude sequences that are normally not considered default grapheme clusters. However, they do not have to catch edge cases that will not occur in practice.
The definition of default grapheme clusters is not meant to exclude the use of more sophisticated definitions of tailored grapheme clusters where appropriate: definitions that more precisely match the user expectations within individual languages. For example, “ch” may be considered a grapheme cluster in Slovak. It is, however, designed to provide a much more accurate match to overall user expectations for characters than is provided by individual Unicode code points.
Display of Grapheme Clusters. Grapheme clusters are not the same as ligatures. For example, the grapheme cluster “ch” in Slovak is not normally a ligature, and conversely, the ligature “fi” is not a grapheme cluster. Default grapheme clusters do not necessarily reflect text display. For example, the sequence <f, i> may be displayed as a single glyph on the screen, but would still be two grapheme clusters.
For more information on the use of grapheme clusters, see UTR #18: Unicode Regular Expression Guidelines [Reports].
Note: As with the other default specifications, implementations are free to override (tailor) the results to meet the requirements of different environments or particular languages.
Table 1. Default Grapheme Cluster Boundaries
| CR | U+000D CARRIAGE RETURN (CR) |
| LF | U+000A LINE FEED (LF) |
| Control | General_Category = Line Separator (Zl), or General_Category = Paragraph Separator (Zp), or General_Category = Control (Cc), or General_Category = Format (Cf) |
| Extend | General Category = Non-spacing Mark (Mn), General_Category = Enclosing Mark (Me), or Other_Grapheme_Extend = true* |
| L | Hangul leading jamo: U+1100 (ᄀ) HANGUL CHOSEONG KIYEOK ..U+115F (ᅟ) HANGUL CHOSEONG FILLER |
| V | Hangul vowel jamo: U+1160 (ᅠ) HANGUL JUNGSEONG FILLER ..U+11A2 (ᆢ) HANGUL JUNGSEONG SSANGARAEA |
| T | Hangul trailing jamo: U+11A8 (ᆨ) HANGUL JONGSEONG KIYEOK ..U+11F9 (ᇹ) HANGUL JONGSEONG YEORINHIEUH |
| LV | Any Hangul syllable that is canonically equivalent to a sequence of <L,V>: U+AC00 (가) HANGUL SYLLABLE GA U+AC1C (개) HANGUL SYLLABLE GAE U+AC38 (갸) HANGUL SYLLABLE GYA ... |
| LVT | Any Hangul syllable that is canonically equivalent to a sequence of <L,V,T>: U+AC01 (각) HANGUL SYLLABLE GAG U+AC02 (갂) HANGUL SYLLABLE GAGG U+AC03 (갃) HANGUL SYLLABLE GAGS U+AC04 (간) HANGUL SYLLABLE GAN ... |
| Any | Any character (includes all of the above) |
|
Break at the start and end of text. |
|||
| sot | ÷ | (1) | |
| ÷ | eot | (2) | |
|
Do not break between a CR and LF. Otherwise break before and after controls. |
|||
| CR | × | LF | (3) |
| Control | ÷ | (4) | |
| ÷ | Control | (5) | |
|
Do not break Hangul syllable sequences. |
|||
| L | × | ( L | V | LV | LVT ) | (6) |
| ( LV | V ) | × | ( V | T ) | (7) |
| ( LVT | T) | × | T | (8) |
|
Do not break before extending characters. |
|||
| × | Extend | (9) | |
|
Otherwise, break everywhere. |
|||
| Any | ÷ | Any | (10) |
Notes:
Other_Grapheme_Extend will be modified in a future version of the UCD to include the following characters:
U+09BE ( ◌া
) BENGALI VOWEL SIGN AA
U+09D7 ( ◌ৗ
) BENGALI AU LENGTH MARK
U+0B3E ( ◌ା
) ORIYA VOWEL SIGN AA
U+0B57 ( ◌ୗ
) ORIYA AU LENGTH MARK
U+0BBE ( ◌ா )
TAMIL VOWEL SIGN AA
U+0BD7 ( ◌ௗ )
TAMIL AU LENGTH MARK
U+0CC2 ( ◌ೂ
) KANNADA VOWEL SIGN UU
U+0CD5 ( ◌ೕ
) KANNADA LENGTH MARK
U+0CD6 ( ◌ೖ
) KANNADA AI LENGTH MARK
U+0D3E ( ◌ാ
) MALAYALAM VOWEL SIGN AA
U+0D57 ( ◌ൗ
) MALAYALAM AU LENGTH MARK
U+0DCF ( ◌ා
) SINHALA VOWEL SIGN AELA-PILLA
U+0DDF ( ◌ෟ
) SINHALA VOWEL SIGN GAYANUKITTA
U+FF9E (゙)
HALFWIDTH KATAKANA VOICED SOUND MARK
U+FF9F (゚)
HALFWIDTH KATAKANA SEMI-VOICED SOUND MARK
U+1D165 ( ◌������
) MUSICAL SYMBOL COMBINING STEM
U+1D16E ( ◌������
) MUSICAL SYMBOL COMBINING FLAG-1
U+1D16F ( ◌������
) MUSICAL SYMBOL COMBINING FLAG-2
Word boundaries are used in a number of different contexts. The most familiar ones are double-click mouse selection, “move to next word” control-arrow keys, and “Whole Word Search” (WWS) for search and replace. They are also used in database queries, to determine whether elements are within a certain number of words of one another.
Word boundaries can also be used in so-called intelligent cut and paste. With this feature, if the user cuts a piece of text on word boundaries, adjacent spaces are collapsed to a single space. For example, cutting “quick” from “The_quick_fox” would leave “The_ _fox”. Intelligent cut and paste collapses this text to “The_fox”.
Here is an example of word boundaries.
| The | quick | ( | “ | brown | ” | ) | fox | can’t | jump | 32.3 | feet | , | right | ? |
There is a boundary, for example, on either side of the word brown. These are the boundaries that users would expect, for example, if they chose WWS. Matching brown with WWS works, since there is a boundary on either side. Matching brow doesn’t. Matching “brown” also works, since there are boundaries between the parentheses and the quotation marks.
For proximity tests, one sees whether, for example, “monster” is within 3 words of “truck”. That is done with the above boundaries by ignoring any words that do not contain a letter, as in Example 2 below. Thus for proximity, “fox” is within three words of “quick”. This same technique can be used for “get next/previous word” commands or keyboard arrow-keys. Letters are not the only characters that can be used to determine the “significant” words: different implementations may include other types of characters such as digits, or perform other analysis of the characters.
| The | quick | brown | fox | can’t | jump | 32.3 | feet | right |
The word boundaries are related to the line boundaries, but are distinct: there are some word-break boundaries that are not line-break boundaries and vice-versa. However, it is relatively seldom that a line-break boundary is not a word-break boundary. One example is a word containing a SHY (soft hyphen). It will break across lines, yet is a single word.
Note: As with the other default specifications, implementations are free to override (tailor) the results to meet the requirements of different environments or particular languages.
Table 2. Default Word Boundaries
| Format | General_Category = Format (Cf) |
| Katakana | Script = KATAKANA, or Any of the following: U+30FC (ー) KATAKANA-HIRAGANA PROLONGED SOUND MARK U+FF70 (ー) HALFWIDTH KATAKANA-HIRAGANA PROLONGED SOUND MARK U+FF9E (゙) HALFWIDTH KATAKANA VOICED SOUND MARK U+FF9F (゚) HALFWIDTH KATAKANA SEMI-VOICED SOUND MARK |
| ALetter | Alphabetic = true, or Any of the following modifier letters: U+02B9 (ʹ) MODIFIER LETTER PRIME U+02BA (ʺ) MODIFIER LETTER DOUBLE PRIME U+02C2 (˂) MODIFIER LETTER LEFT ARROWHEAD ..U+02CF (ˏ) MODIFIER LETTER LOW ACUTE ACCENT U+02D2 (˒) MODIFIER LETTER CENTRED RIGHT HALF RING ..U+02DF (˟) MODIFIER LETTER CROSS ACCENT U+02E5 (˥) MODIFIER LETTER EXTRA-HIGH TONE BAR ..U+02ED (˭) MODIFIER LETTER UNASPIRATED U+05F3 (׳) HEBREW PUNCTUATION GERESH and not Ideographic = true and not Katakana = true and not Script = Thai and not Script = Lao and not Script = Hiragana |
| MidLetter | Any of the following: U+0027 (') APOSTROPHE U+00AD ( ) SOFT HYPHEN U+00B7 (·) MIDDLE DOT U+05F4 (״) GERSHAYIM U+2019 (’) RIGHT SINGLE QUOTATION (curly apostrophe) U+2027 (‧) HYPHENATION POINT |
| MidNumLet | Any of the following: U+002E (.) FULL STOP (period) U+003A (:) COLON (used in Swedish) |
| MidNum | Line_Break = Infix_Numeric and not MidNumLet = true |
| other | Other categories are from Line_Break (using the long names from PropertyAliases) |
|
Break at the start and end of text. |
|||
| sot | ÷ | (1) | |
| ÷ | eot | (2) | |
|
Treat a grapheme cluster as if it were a single character: the first character of the cluster. |
|||
|
GC |
→ |
FB | (3) |
|
Ignore interior Format characters. That is, ignore Format characters in all subsequent rules (except the last rule). |
|||
| X Format* | → | X | (4) |
|
Do not break between most letters. |
|||
| ALetter | × | ALetter | (5) |
|
Do not break letters across certain punctuation. |
|||
| ALetter | × | (MidLetter | MidNumLet) ALetter | (6) |
| ALetter (MidLetter | MidNumLet) | × | ALetter | (7) |
|
Do not break within sequences of digits, or digits adjacent to letters ('3a', or 'A3'). |
|||
| Numeric | × | Numeric | (8) |
| ALetter | × | Numeric | (9) |
| Numeric | × | ALetter | (10) |
|
Do not break within sequences like: ‘3.2’ or '3,456.789'. |
|||
| Numeric (MidNum | MidNumLet) | × | Numeric | (11) |
| Numeric | × | (MidNum | MidNumLet) Numeric | (12) |
|
Do not break between Katakana. |
|||
| Katakana | × | Katakana | (13) |
|
Otherwise, break everywhere (including around ideographs). |
|||
| Any | ÷ | Any | (14) |
Unfortunately not all issues can be resolved across languages (or even within a language, since there are ambiguities). The goal is to have as workable a default as possible; tailored engines can be more sophisticated about these matters.
For Thai, Lao, Khmer, Mynmar, and other scripts that don't use typically use spaces between words, a good implementation should not just depend on the default word boundary specification, but should use a more sophisticated mechanism, as in LineBreak. Ideographic scripts such as Japanese and Chinese are even more complex. Where Hangul text is written without spaces, the same applies. However, in the absence of such a more sophisticated mechanism, the above at least supplies a well-defined default.
The hard hyphen is a tricky case. It is quite common for separate words to be connected with a hyphen: out-of-the-box, under-the-table, Anglo-american, etc. A significant number are hyphenated names: Smith-Hawkins, etc. When people do a “Whole Word” search or query, they expect to find the word within those hyphens. While there are some cases where they are separate words (usually to resolve some ambiguity such as re-sort vs. resort) it’s better overall to keep the hard hyphen out of the default definition.
Apostrophe is another tricky case. Usually considered part of one word (“can’t”, “aujourd’hui”) it may also be considered two (“l’objectif”). Also, one cannot easily distinguish the cases where it is used as a quotation mark from those where it is used as an apostrophe, so one should not include leading or trailing apostrophes. In some languages, such as French and Italian, tailoring it to break words when the character after the apostrophe is a vowel may yield better results in more cases. This can be done by adding a rule 5a:
|
Break between hyphens and vowels (French, Italian) |
|||
| hyphens | ÷ | vowels | (5a) |
and defining appropriate property values for hyphens and vowels.
Certain cases like colon in words (c:a) are included even though they may be specific to relatively small user communities (Swedish) because they don’t occur otherwise in normal text, and so don’t cause a problem for other languages.
For Hebrew, a tailoring may include a double quotation mark between letters, since legacy data may contain that in place of U+05F4 (״) gershayim. This can be done by adding double quotation mark to MidLetter.
Format characters are ignored if they are interior. Thus <LRM><letter> will break, and <letter><LRM> will break, but there is no break in <letter><LRM><letter>.
Sentence boundaries are often used for triple-click or some other method of selecting or iterating through blocks of text that are larger than single words. They are also used to determine whether words occur within the same sentence in database queries.
Plain text provides inadequate information for determining good sentence boundaries. Periods, for example, can either signal the end of a sentence, indicate abbreviations, or be used for decimal points. One cannot, without much more sophisticated analysis, distinguish between the two following cases:
He said, “Are you going?” John shook his head.
“Are you going?” John asked.
Without analyzing the text semantically, it is impossible to be certain which of these usages is intended (and sometimes ambiguities still remain). However, in a large majority of cases, a straightforward mechanism works well.
Note: As with the other default specifications, implementations are free to override (tailor) the results to meet the requirements of different environments or particular languages.
Table 3. Default Sentence Boundaries
| Sep | Any of the following characters: U+000A LINE FEED (LF) U+000D CARRIAGE RETURN (CR) U+0085 NEXT LINE (NEL) U+2028 LINE SEPARATOR (LS) U+2029 PARAGRAPH SEPARATOR (PS) |
| Format | General_Category = Format (Cf) |
| Sp | Whitespace = true and not Sep = true |
| Lower | Lowercase = true |
| Upper | General_Category = Titlecase_Letter (Lt), or Uppercase = true |
| OLetter | Alphabetic = true, or Any of the following modifier letters: U+02B9 (ʹ) MODIFIER LETTER PRIME U+02BA (ʺ) MODIFIER LETTER DOUBLE PRIME U+02C2 (˂) MODIFIER LETTER LEFT ARROWHEAD ..U+02CF (ˏ) MODIFIER LETTER LOW ACUTE ACCENT U+02D2 (˒) MODIFIER LETTER CENTRED RIGHT HALF RING ..U+02DF (˟) MODIFIER LETTER CROSS ACCENT U+02E5 (˥) MODIFIER LETTER EXTRA-HIGH TONE BAR ..U+02ED (˭) MODIFIER LETTER UNASPIRATED U+05F3 (׳) HEBREW PUNCTUATION GERESH and not Lower = true and not Upper = true |
| Numeric | Linebreak = Numeric (NU) |
| Close | General_Category = Open_Punctuation (Po), or General_Category = End_Punctuation (Pe), or Linebreak = Quotation (QU) |
| ATerm | Any of the following characters: U+002E (.) FULL STOP |
| Term | Any of the following characters: U+0021 (!) EXCLAMATION MARK U+003F (?) QUESTION MARK U+0589 (։) ARMENIAN FULL STOP U+061F (؟) ARABIC QUESTION MARK U+06D4 (۔) ARABIC FULL STOP U+0700 (܀) SYRIAC END OF PARAGRAPH U+0701 (܁) SYRIAC SUPRALINEAR FULL STOP U+0702 (܂) SYRIAC SUBLINEAR FULL STOP U+0964 (।) DEVANAGARI DANDA U+1362 (።) ETHIOPIC FULL STOP U+1367 (፧) ETHIOPIC QUESTION MARK U+1368 (፨) ETHIOPIC PARAGRAPH SEPARATOR U+104A (၊) MYANMAR SIGN LITTLE SECTION U+104B (။) MYANMAR SIGN SECTION U+166E (᙮) CANADIAN SYLLABICS FULL STOP U+1803 (᠃) MONGOLIAN FULL STOP U+1809 (᠉) MONGOLIAN MANCHU FULL STOP U+203C (‼) DOUBLE EXCLAMATION MARK U+203D (‽) INTERROBANG U+2047 (⁇) DOUBLE QUESTION MARK U+2048 (⁈) QUESTION EXCLAMATION MARK U+2049 (⁉) EXCLAMATION QUESTION MARK U+3002 (。) IDEOGRAPHIC FULL STOP U+FE52 (﹒) SMALL FULL STOP U+FE57 (﹗) SMALL EXCLAMATION MARK U+FF01 (!) FULLWIDTH EXCLAMATION MARK U+FF0E (.) FULLWIDTH FULL STOP U+FF1F (?) FULLWIDTH QUESTION MARK U+FF61 (。) HALFWIDTH IDEOGRAPHIC FULL STOP |
|
Break at the start and end of text. |
|||
| sot | ÷ | (1) | |
| ÷ | eot | (2) | |
|
Break after paragraph separators. |
|||
| Sep | ÷ | (3) | |
|
Treat a grapheme cluster as if it were a single character: the first character of the cluster. |
|||
|
GC |
→ |
FB | (4) |
|
Ignore interior Format characters. That is, ignore Format characters in all subsequent rules. |
|||
| X Format* | → | X | (5) |
|
Do not break after ambiguous terminators like period, if immediately followed by a number or lowercase letter, is between uppercase letters, or if the first following letter (optionally after certain punctuation) is lowercase. For example, a period may be an abbreviation or numeric period, and not mark the end of a sentence. |
|||
| ATerm | × | ( Numeric | Lower ) | (6) |
| Upper ATerm | × | Upper | (7) |
| ATerm Close* Sp* | × | ( ¬(OLetter | Upper | Lower) )* Lower | (8) |
|
Break after sentence terminators, but include closing punctuation, trailing spaces, and (optionally) a paragraph separator. |
|||
| ( Term | ATerm ) Close* | × | ( Close | Sp | Sep ) | (9) |
| ( Term | ATerm ) Close* Sp | × | ( Sp | Sep ) | (10) |
| ( Term | ATerm ) Close* Sp* | ÷ | (11) | |
|
Otherwise, do not break |
|||
| Any | × | Any | (12) |
Notes:
Rules 6-8 are designed to forbid breaks within strings like:
| c.d |
| 3.4 |
| U.S. |
| ... the resp. leaders are ... |
| ... etc.)’ ‘(the ... |
while permitting breaks in strings like:
| She said “See spot run.” | John shook his head. ... |
| ... etc. | 它们指... |
| ...理数字. | 它们指... |
As discussed above, they cannot detect cases like “Mr. Jones”; more sophisticated tailoring would be required for that.
Although boundaries are specified in terms of NFD text, in practice normalization is not required. The Grapheme Cluster specification has a number of features to are to ensure that the same results are returned for canonically equivalent text. It will not break within a sequence of non-spacing marks, which is the only part that can reorder in the formation of NFD. Nor is there ever a break between a base character and subsequent non-spacing marks. It also has a special set of characters marked as having the Extend property value, such as U+09BE ( ◌া ) BENGALI VOWEL SIGN AA, to deal with particular compositions.
The other default boundary specifications never break within grapheme clusters, and always use a consistent property value for each grapheme cluster as a whole.
The first rule for the default word and sentence specifications is to treat a grapheme cluster as a single character: the first character of the cluster. This would be equivalent to making the following changes to the subsequent rules.
The other special rule for the word and sentence specifications is to ignore interior Format characters. This would be equivalent to making the following further changes to the affected subsequent rules.
The above rules can be converted into a regular expression that will produce the same results. The regular expression must be evaluated starting at a known boundary (such as the start of the text), and take the longest match (except in the case of Sentence boundaries, where the shortest match needs to be used).
The conversion into a regular expression is fairly straightforward, although it takes a little thought. For example, Table 1. Default Grapheme Cluster Boundaries can be transformed into the following regular expression:
Control
| CR LF
| ( !Control? | L+ | T+ | L* ( LV? V+ | LV | LVT ) T* ) Extend*
Such a regular expression can then be turned into a very fast state machine. For more information on Unicode Regular Expressions, see UTR #18: Unicode Regular Expression Guidelines [Reports].
A further complication is introduced by random access. When iterating through a string from beginning to end, a regular expression / state machine works well. From each boundary to find the next boundary is very fast. By constructing a state table for the reverse direction from the same specification of the rules, reverse iteration is possible.
However, suppose that the user wants to iterate starting at a random point in the text, or detect whether a random point in the text is a boundary. If the starting point does not provide enough context to allow the correct set of rules to be applied, then one could fail to find a valid boundary point. For example, suppose a user clicked after the first space after the question mark in “Are_you_there? _ _ No,_I'm_not”. On a forward iteration searching for a sentence boundary, one would fail to find the boundary before the “N”, because the “?” hadn’t been seen yet.
A second set of rules to determine a “safe” starting point provides a solution. Iterate backward with this second set of rules until a safe starting point is located, then iterate forward from there. Iterate forward to find boundaries that were located between the safe point and the starting point; discard these. The desired boundary is the first one that is not less than the starting point. The safe rules must be designed so that they function correctly no matter what the starting point is, so they have to be conservative in terms of finding boundaries: only finding those boundaries that can be determined by a small context.
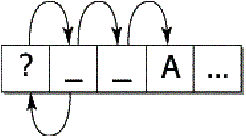
This process would represent a significant performance cost if it had to be performed on every search. However, this functionality can be wrapped up in an iterator object, which preserves the information regarding whether it currently is at a valid boundary point. Only if it is reset to an arbitrary location in the text is this extra backup processing performed. The iterator may even cache local values that it has already traversed.
State machines can also be combined with a code-based or table-based tailoring mechanism. For typical Unicode state machines, a Unicode character is typically passed to a mapping table that maps characters to boundary property values. This mapping can use an efficient mechanism such as a trie. Once a boundary property value is produced, then it is passed to the state machine.
The simplest customization is just to adjust the values coming out of the character mapping table. For example, to mark the appropriate quotation marks for a given language as having the Close sentence boundary property, artificial property values can be introduced for different quotation marks. A table can be applied after the main mapping table to map those artificial character property values to the real ones. To change languages, a different small table is substituted. The only real cost is then an extra array look-up.
For code-based tailoring a different special range of property values can be added. The state machine is set up so that any special property value causes the state machine to halt, and return a particular exception value. When this exception value is detected, the higher-level process can call specialized code according to whatever the exceptional value is. This can all be encapsulated so that it is transparent to the caller.
For example, Thai characters can be mapped to a special property value. When the state machine halts for one of these values, then a Thai word-break engine is invoked internally, to produce boundaries within the subsequent string of Thai characters. These boundaries can then be cached so that subsequent calls for next/previous boundaries merely return the cached values. Similarly Lao characters can be mapped to a different special property value, causing a different engine to be invoked.
There is no requirement by Unicode-conformant implementations to implement these default boundaries. As with the other default specifications, implementations are also free to override (tailor) the results to meet the requirements of different environments or particular languages. For those who do implement the default boundaries as specified above, and wish to check that that their implementation matches that specification, three test files have been made available.
These tests cannot be exhaustive, because of the sheer combinatorics; but they do provide samples that test all pairs of property values, using a representative character for each value, plus certain other sequences.
| Test Data | Chart |
|---|---|
| GraphemeClusterBreakTest.txt | GraphemeClusterBreakTest.html |
| WordBreakTest.txt | WordBreakTest.html |
| SentenceBreakTest.txt | SentenceBreakTest.html |
A sample HTML file is also available that shows various combinations in chart form. The header cells of the chart consist of a property value, followed by a representative code point number. The body cells in the chart show the break status: whether a break occurs between the row property value and the column property value. If the browser supports tool-tips, then hovering the mouse over the code point number will show the character name, general category, line break, and script property values. Hovering over the break status will display the number of the rule responsible for that status.
The chart may be followed by some test cases. These test cases consist of various strings with the break status between each pair of characters shown by blue lines for breaks, and whitespace for non-breaks. Hovering over each character (with tool-tips enabled) shows the character name and property value; hovering over the break status shows the number of the rule responsible for that status.
Thanks to Ted Hopp, Andy Heninger, and Eric Mader for their feedback on previous versions of this document.
| [FAQ] | Unicode Frequently Asked Questions http://www.unicode.org/unicode/faq/ For answers to common questions on technical issues. |
| [Glossary] | Unicode Glossary http://www.unicode.org/glossary/ For explanations of terminology used in this and other documents. |
| [Reports] | Unicode Technical Reports http://www.unicode.org/unicode/reports/ For information on the status and development process for technical reports, and for a list of technical reports. |
| [U3.2] | Unicode Standard Annex #28: Unicode 3.2 http://www.unicode.org/unicode/reports/tr28/ |
| [Versions] | Versions of the Unicode Standard http://www.unicode.org/unicode/standard/versions/ For details on the precise contents of each version of the Unicode Standard, and how to cite them. |
The following summarizes modifications from the previous versions of this document.
Copyright © 2000-2002 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.