L2/02-083
Response and Proposal for Khmer Encoding
By: Paul Nelson, 2 December 2001
During the 41st WG2 Meeting in Singapore, the Cambodian government submitted an official objection to the existing Khmer block in Unicode 3.0 and proposed a new encoding to replace the existing Khmer block. This paper is intended to provide comments and a point of view for discussion in response to the Cambodian documents and the Everson/Bauhahn documents.
Response
- The existing Khmer characters (consonants, independent vowels, dependent vowel signs and other signs) must remain as they are currently encoded in Unicode. This is critical to maintain order in the standard. While the current encoding may not be ideal, it has been published nonetheless. It is acknowledged that there may not have been official signoff by representatives of the Cambodian government on the standard when it was created a couple of years ago. History cannot be changed at this point. We can only hope that there will be an open Cambodian participation in the Khmer encoding process moving forward.
- Characters proposed by the Cambodian delegation that are not included in the Khmer Unicode block should be added if they do not duplicate characters which can be generated by the current Unicode encoding mechanism. See the proposal following.
- The COENG encoding model should not be considered as being synonymous with the “virama” model. The COENG encoding model does not encompass all of the behaviors as the virama does for Indic languages. Therefore, it is suggested that “COENG encoding model” should be used when speaking of Khmer script usage. Any wording or semantics referring to the virama should be removed from the Unicode standard when discussing Khmer script.
- The existing COENG encoding model should be maintained for the scope in which it provides a consistent and workable solution.
- It is acknowledged that the COENG encoding model does require additional size for storing documents.
- It is acknowledged that the COENG encoding model may have slightly slower performance for sorting and rendering text.
- It is acknowledged that some people view the COENG encoding model as a foreign convention that is being forced on the modern Khmer language users. It is also acknowledged that some people may view the COENG model as something that is a cultural assault on them as Cambodians.
- After reflecting on the issue and weighing out the pros and cons, it seems that items a. and b. above are not significant enough issues to require a change to the COENG encoding model. The costs of moving from the COENG encoding model to an encoded subscript model are: 1) the necessity of invalidating all existing Khmer Unicode data and implementations, 2) the necessity of deprecating the COENG character, 3) adding all of the subscript characters, and 4) most critical the change would introduce a destabilizing factor into the ISO and Unicode standards because others would view this as a precedent to change other areas as well.
- The COENG + KA combination is exactly the same as explicitly encoding the COENG KA subscript form. In any place the proposed replacement encoding represents and uses the encoded subscript form of a letter, it is equal to use the existing Khmer Unicode standard to represent the subscript by COENG + the base character from which that subscript form is derived.
i. The COENG model requires the following consonant or independent vowel to be “glued” to the COENG and be treated as a unit from that time on. Places this “glued” combination are required include, but are not limited to, rendering, collation/sorting, determining caret position, copying and pasting text, etc.
ii. The COENG letter combination functions as a diacritic or combining mark to the base character.
- The existing COENG encoding model does not correctly handling lunar dates. I propose that the Lunar Date Symbols (LDS) proposed by the Cambodian delegation be encoded in a new Extended Khmer block to be located near the range of U+19E0 – U+19FF. This needed addition of Lunar Date Symbols is due to the different behavior of lunar dates vis-à-vis consonants; that is, the LDS cannot be used within the definition of the COENG encoding model.
- The COENG encoding model says that the vowel of the preceding consonant is killed. This does not apply to lunar dates.
- The COENG encoding model says that the following letter should be treated as a subscript. The formation of the lunar date has the second number in a subscript form. However, the preceding number is made into a smaller size and put into a superscript form.
- Lunar date symbols may have one or two digits above, or one or two digits below. Having more than one digit in either position causes the COENG encoding model to not work correctly. Therefore, the COENG model should not be construed as also working for lunar dates.
- For the COENG encoding model to handle the ROBAT, as contended by Bauhahn, an exception to the definition of the COENG encoding model (4.b. above) is required for this special case. This introduces an alternative manner in which the ROBAT is encoded and causes issues with normalization and canonical ordering. While the point that encoding the ROBAT using the COENG encoding model in the order suggested by Bauhahn solves sorting issues, it must be pointed out that that encoding and sorting are two completely different concepts, and collation should not be improved or fixed by suggesting changes to the repertoire. Thus, if encoding the ROBAT as Bauhahn suggests is seriously considered, 1) the ROBAT character should be deprecated so that only one method of forming the ROBAT remains and 2) an exception to the COENG encoding model must be introduced. Input from the Cambodian delegation is critical to correctly understanding this issue.
Proposed Encoding Changes
The following charts include characters that should be added to Unicode to support Khmer.
Abstract: In the process of originally encoding the Khmer script, some commonly used characters were not encoded. It is proposed that the characters listed be added to the current Khmer block to allow modern Khmer documents to be created. The characters added are grouped into six areas.
- Additional Diacritic Signs –
- Repeater Sign –
- Divination Lore Signs –
- Pali/Sanskrit extending sign –
- Variant Selector – The variant selector is used to resolve ambiguous cases where the same letter may take different shapes.
- Lunar Date Symbols -
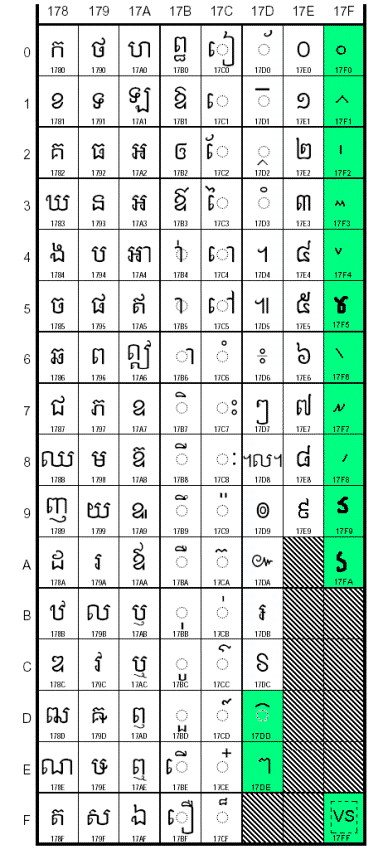
Additional Diacritic Signs
17DD – KHMER SIGN ATTHACAN;Mn;0;NSM;;;;;N;;;;;
Repeater Sign
17DE – KHMER SIGN
LEKTO;Po;0;L;;;;;N;;;;;
Digit symbols for divination lore
17F0 – KHMER SYMBOL LEK ATTAK SON;Nd;0;L;;0;0;0;N;;;;;
17F1 – KHMER SYMBOL LEK ATTAK MUOY;Nd;0;L;;0;0;0;N;;;;;
17F2 – KHMER SYMBOL LEK ATTAK PII;Nd;0;L;;0;0;0;N;;;;;
17F3 – KHMER
SYMBOL LEK ATTAK BEI;Nd;0;L;;0;0;0;N;;;;;
17F4 – KHMER SYMBOL LEK ATTAK BUON;Nd;0;L;;0;0;0;N;;;;;
17F5 – KHMER SYMBOL LEK ATTAK PRAM;Nd;0;L;;0;0;0;N;;;;;
17F6 – KHMER SYMBOL LEK ATTAK PRAM-MUOY;Nd;0;L;;0;0;0;N;;;;;
17F7 – KHMER SYMBOL LEK ATTAK PRAM-PII;Nd;0;L;;0;0;0;N;;;;;
17F8 – KHMER
SYMBOL LEK ATTAK PRAM-BEI;Nd;0;L;;0;0;0;N;;;;;
17F9 – KHMER SYMBOL LEK ATTAK PRAM-BUON;Nd;0;L;;0;0;0;N;;;;;
Pali/Sanskrit extending sign
17FA – KHMER SIGN AVAKRAHA;Po;0;L;;;;;N;;;;;
Control Character
17FF – KHMER VARIANT SIGN;Cf;0;BN;;;;;N;;;;;
Khmer Extended -
The proposed Khmer Extended block includes lunar date symbols that are used with Khmer. The proposed range is U+19E0 – U+19FF.
Sorting order – The sorting order of the Khmer Extended block should be in the order of the Unicode characters. [this should be confirmed or correct sort order given]
Typographical form of Khmer lunar dates – The typographical form of Khmer lunar dates is a top and bottom section of the same size text. The dividing line between the upper an lower half of the symbol is the vertical center of the line height.

Lunar Date Symbols
19E0 – KHMER
SYMBOL PATHAMASAT;No;0;L;;0;0;0;N;;;;;
19E1 – KHMER
SYMBOL MUOY KOET;No;0;L;;0;0;0;N;;;;;
19E2 – KHMER
SYMBOL PII KOET;No;0;L;;0;0;0;N;;;;;
19E3 – KHMER
SYMBOL BEI KOET;No;0;L;;0;0;0;N;;;;;
19E4 – KHMER
SYMBOL BUON KOET;No;0;L;;0;0;0;N;;;;;
19E5 – KHMER
SYMBOL PRAM KOET;No;0;L;;0;0;0;N;;;;;
19E6 – KHMER
SYMBOL PRAM-MUOY KOET;No;0;L;;0;0;0;N;;;;;
19E7 – KHMER
SYMBOL PRAM-PII KOET;No;0;L;;0;0;0;N;;;;;
19E8 – KHMER
SYMBOL PRAM-BEI KOET;No;0;L;;0;0;0;N;;;;;
19E9 – KHMER
SYMBOL PRAM-BUON KOET;No;0;L;;0;0;0;N;;;;;
19EA – KHMER
SYMBOL DAP KOET;No;0;L;;0;0;0;N;;;;;
19EB – KHMER
SYMBOL DAP-MUOY KOET;No;0;L;;0;0;0;N;;;;;
19EC – KHMER
SYMBOL DAP-PII KOET;No;0;L;;0;0;0;N;;;;;
19ED – KHMER
SYMBOL DAP-BEI KOET;No;0;L;;0;0;0;N;;;;;
19EE – KHMER
SYMBOL DAP-BUON KOET;No;0;L;;0;0;0;N;;;;;
19EF – KHMER
SYMBOL DAP-PRAM KOET;No;0;L;;0;0;0;N;;;;;
19F0 – KHMER
SYMBOL TUTEYASAT;No;0;L;;0;0;0;N;;;;;
19F1 – KHMER SYMBOL MUOY ROC;No;0;L;;0;0;0;N;;;;;
19F2 – KHMER SYMBOL PII ROC;No;0;L;;0;0;0;N;;;;;
19F3 – KHMER SYMBOL BEI ROC;No;0;L;;0;0;0;N;;;;;
19F4 – KHMER SYMBOL BUON ROC;No;0;L;;0;0;0;N;;;;;
19F5 – KHMER SYMBOL PRAM ROC;No;0;L;;0;0;0;N;;;;;
19F6 – KHMER SYMBOL PRAM-MUOY ROC;No;0;L;;0;0;0;N;;;;;
19F7 – KHMER SYMBOL PRAM-PII ROC;No;0;L;;0;0;0;N;;;;;
19F8 – KHMER
SYMBOL PRAM-BEI ROC;No;0;L;;0;0;0;N;;;;;
19F9 – KHMER
SYMBOL PRAM-BUON ROC;No;0;L;;0;0;0;N;;;;;
19FA – KHMER
SYMBOL DAP ROC;No;0;L;;0;0;0;N;;;;;
19FB – KHMER
SYMBOL DAP-MUOY ROC;No;0;L;;0;0;0;N;;;;;
19FC – KHMER SYMBOL DAP-PII ROC;No;0;L;;0;0;0;N;;;;;
19FD – KHMER SYMBOL DAP-BEI ROC;No;0;L;;0;0;0;N;;;;;
19FE – KHMER SYMBOL DAP-BUON ROC;No;0;L;;0;0;0;N;;;;;
19FF – KHMER SYMBOL DAP-PRAM ROC;No;0;L;;0;0;0;N;;;;;
Compatibility Mappings
Compatibility mapping – [this section needs to be completed] Are these considered as atomic units, or are they considered as being compatible to some combination of numbers? This does not imply that they would be decomposed or formed from decomposed forms. It does provide for some default sorting behaviors.