Date: Sun, 5 Nov 2017 21:55:53 -0800
I had some time on the plane this weekend, and generated some more
comprehensive figures that take the following into account:
1. There are two senses of "Unicode". In the narrow sense, it is only
the Unicode Standard (ie, Unicode Characters). But it has grown to have a
more comprehensive sense, including the other two main projects of the
Unicode Consortium: Unicode CLDR and ICU.
2. The ca. 3,300 pages that Asmus cited include specification *text*
alone, but *data/code* (eg, UCD property data, or source code for ICU)
is a vital part of the projects.
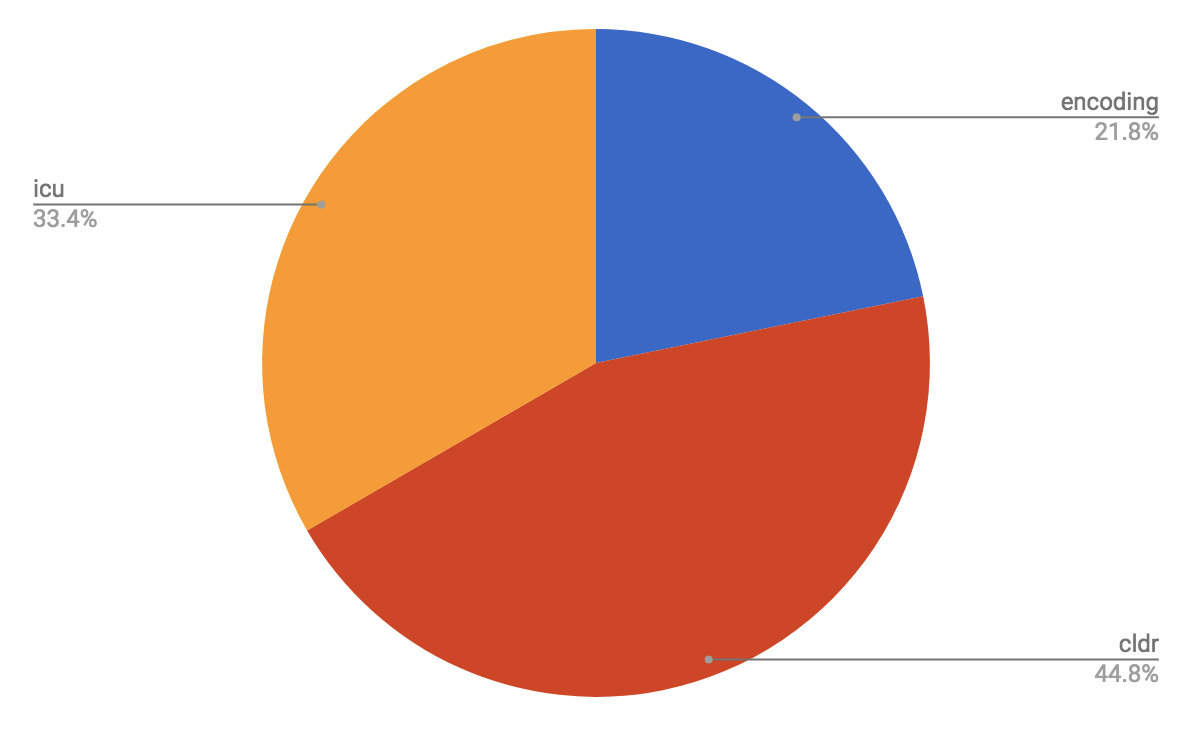
I thus generated a rough comparison where I (a) included CLDR and ICU, and
(b) included data. That gave the following results (where "encoding"
includes both the Unicode Standard *and* UTS's that are aligned with it in
version, including emoji — since that is to be aligned with it).
[image: Inline image 1]
*Caveats*
- *This is a rough approximation (my flight wasn't all that long...).*
In particular, don't count on the 3 decimals of precision — that is just
the spreadsheet charting.
- For the data files and code files, I filtered by removing # comments,
collapsing sequences of whitespace into a single space character, trimming
whitespace, and tossing empty lines. I then counted a page as a total of 3K
code points. So the page count for data and code is far smaller than simply
a line count. (Didn't bother dropping // and /*...*/ comments in code.) I
also excluded .txt files that had the word "test" (case-insensitive) in
their names.
- For html pages I took a few samples of PDFs for UTS's and ICU docs,
and got a count of HTML code points per page for each generated type of
page, then divided out to get an approximate page count.
- There were some other filters: for example, for ICU sources I included
only files of type {"cpp", "c", "h", "ucm", "java"}, since files of type
"txt" were likely generated from CLDR data. For CLDR I excluded charts and
Survey Tool pages, since that would have bulked up the CLDR pie-slice
drammatically.
- (And by the way, the pie-slice for emoji is not visible in this graph:
just 0.1%.)
Mark <https://twitter.com/mark_e_davis>
On Fri, Nov 3, 2017 at 2:36 AM, Asmus Freytag via Unicode <
unicode_at_unicode.org> wrote:
> On 11/3/2017 2:13 AM, Andre Schappo via Unicode wrote:
>
>
> You may find https://twitter.com/andreschappo/status/926163719331176450 amusing
> 😀
>
> André Schappo
>
> You're wildly off in your page count.
>
> The "book" part of Unicode (Core Specification) alone is 1,500 pages. I
> haven't looked at the single file code charts in a while, but I believe you
> get at least that number again. Then add the dozen or so "Annexes" for a
> few hundred additional pages and be happy that nobody prints the Unicode
> Character Database (or the Unihan Database for that matter).
>
> A./
>