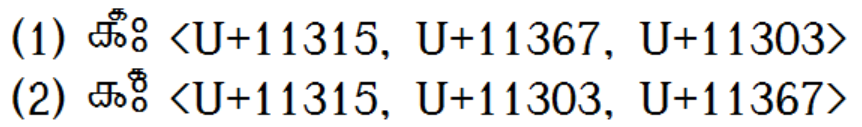Date: Sat, 4 Jan 2020 22:15:59 +0000
On 2020-01-04 12:50 PM, Richard Wordingham via Unicode wrote:
> dev2: कः꣡ <U+915 LETTER KA, U+903 VISARGA, U+A8E1 COMBINING DEVANAGARI
> DIGIT ONE>
>
> dev3: क꣡ः <U+0915, U+A8E1, U+0903>
> Grantha: (1) 𑌕𑍧𑌃 <U+11315 LETTER KA, U+11367 COMBINING GRANTHA DIGIT
> ONE, U+11303 VISARGA>
> (2) 𑌕𑌃𑍧 <U+11315, U+11303, U+11367>
> The second Grantha spelling is enabled by a Harfbuzz-only change to
> the USE categorisations. It treats Grantha visarga and spacing
> anusvara as though inpc=Top rather than inpc=Right. As I am using
> Ubuntu 16.04, this override isn't supported in applications that use the
> system HarfBuzz library, such as my email client.
>
> We are now establishing incompatible Devanagari font-specific
> encodings fully compliant with TUS!
This seems to be a very bad approach. And apparently it isn't limited
to the Devanagari script.
For the Grantha examples above, Grantha (1) displays much better here.
It seems daft to put a spacing character between a base character and
any mark which is supposed to combine with the base character.