|
|
Technical Reports |
| Version | Unicode 17.0.0 |
| Editors | Ken Whistler |
| Date | 2025-07-31 |
| This Version | https://www.unicode.org/reports/tr34/tr34-32.html |
| Previous Version | https://www.unicode.org/reports/tr34/tr34-31.html |
| Latest Version | https://www.unicode.org/reports/tr34/ |
| Latest Proposed Update | https://www.unicode.org/reports/tr34/proposed.html |
| Revision | 32 |
This annex defines the concept of Unicode named character sequences, specifies a notational convention for them and a set of rules constraining possible names applied to character sequences.
This document has been reviewed by Unicode members and other interested parties, and has been approved for publication by the Unicode Consortium. This is a stable document and may be used as reference material or cited as a normative reference by other specifications.
A Unicode Standard Annex (UAX) forms an integral part of the Unicode Standard, but is published online as a separate document. The Unicode Standard may require conformance to normative content in a Unicode Standard Annex, if so specified in the Conformance chapter of that version of the Unicode Standard. The version number of a UAX document corresponds to the version of the Unicode Standard of which it forms a part.
Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this annex is found in Unicode Standard Annex #41, “Common References for Unicode Standard Annexes.” For the latest version of the Unicode Standard, see [Unicode]. For a list of current Unicode Technical Reports, see [Reports]. For more information about versions of the Unicode Standard, see [Versions]. For any errata which may apply to this annex, see [Errata].
The Unicode Standard specifies notational conventions for referring to sequences of characters (or code points) treated as a unit, using angle brackets surrounding a comma-delimited list of code points, code points plus character names, and so on. For example, both of the designations in Table 1 refer to a combining character sequence consisting of the letter “a” with a circumflex and an acute accent applied to it.
Table 1. Example of a Combining Character Sequence
| <U+0061, U+0302, U+0301> |
| <U+0061 LATIN SMALL LETTER A, U+0302 COMBINING CIRCUMFLEX ACCENT, U+0301 COMBINING ACUTE ACCENT> |
See Appendix A, Notational Conventions, in [Unicode] for the description of the conventions for expression of code points and for the representation of sequences of code points.
The Unicode conventions for referring to a sequence of characters (or code points) are a generalization of the formal syntax specified in ISO/IEC 10646 for UCS Sequence Identifiers, or USI. A USI has the form
<UID1, UID2, ... UIDn>
where the UIDi represent the short identifiers for code points—most commonly “U+0061” or “0061”. A USI must contain at least two code points.
Such a generalized notation for sequences of Unicode code points is often useful in discursive text. More formally, other standards may need to refer to entities that are represented in Unicode by sequences of characters. Mapping tables may map single characters in other standards to sequences of Unicode characters, and listings of repertoire coverage for fonts or keyboards may need to reference entities that do not correspond to single Unicode code points.
In some limited circumstances it is necessary to also provide a name for such sequences. The primary example is the need to have an identifier for a sequence to correlate with an identifier in another standard, for which a cross-mapping to Unicode is desired. To address this need, the Unicode Standard defines a mechanism for naming sequences and provides a list of sequences that have been formally named. This list is deliberately selective: it is neither possible nor desirable to attempt to provide names for all possible sequences of Unicode characters that could be of interest.
This annex defines the concept of a Unicode named character sequence, specifies a notational convention for such sequences, and a set of rules constraining possible names applied to character sequences. Section 5, Data Files, identifies the data file containing the normative list of Unicode named character sequences. As is the case for character names, named character sequences are strictly synchronized with ISO/IEC 10646.
Table 2 provides some examples of Unicode named character sequences to illustrate the kinds of entities that have been formally named. The “Sequence” column illustrates the entity in question with a representative rendering above the sequence of encoded Unicode characters that represent that entity. The “Name” column shows the name that has been associated with that sequence.
Table 2. Examples of Named Character Sequences
| Sequence | Name | Notes on Usage |
|---|---|---|
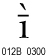 |
LATIN SMALL LETTER I WITH MACRON AND GRAVE | Livonian |
 |
MODIFIER LETTER EXTRA-HIGH EXTRA-LOW CONTOUR TONE BAR | Contour tone letter |
 |
KATAKANA LETTER AINU P | Ainu in kana transcription |
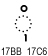 |
KHMER VOWEL SIGN OM | Khmer |
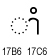 |
KHMER VOWEL SIGN AAM | Khmer |
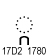 |
KHMER CONSONANT SIGN COENG KA | Khmer |
Unicode named character sequences differ from Unicode variation sequences. The latter are documented in Section 23.4, Variation Selectors in [Unicode] and are listed in the data file StandardizedVariants.txt in the Unicode Character Database [UCD] or in the data file emoji-sequences.txt associated with UTS #51, "Unicode Emoji" [UTS51].
Variation sequences always consist of a sequence of precisely two defined code points, the second of which must be a variation selector. There are additional constraints on which types of characters they can start with. Variation sequences have a restricted range of glyphic shapes, but have no associated name.
Named character sequences can, in principle, consist of code point sequences of any length, without constraints on what types of characters are involved. They do not have a specifically defined glyphic shape, but they do have a formally specified name associated with them.
UAX34-D1. Unicode named character sequence: A specific sequence of two or more Unicode characters, together with a formal name designating that sequence.
UAX34-D2. Unicode namespace: A set of strings used to label entities in some context in the Unicode Standard, together with a rule or list of rules which specify how the strings are constructed and a uniqueness rule which specifies how candidate strings are determined to be unique within the set.
Examples of Unicode namespaces include the namespace for character names themselves, the namespace for character property aliases, and the separate namespace for the property value aliases of each enumerated property.
UAX34-D3. Unicode namespace for character names: The Unicode namespace consisting of Unicode character names, code point labels, character name aliases, and the names for Unicode named character sequences.
Note: It is tempting to refer to the elements of the Unicode namespace for character names just as "character names" for short. However, such practice is misleading and not recommended. The point of this namespace is to provide a guarantee of name uniqueness that encompasses the normative names of Unicode characters, but which also includes certain other labels and names of character-like entities and names of sequences of characters. Formally, the elements are defined by the following list:
- Non-null values of the Unicode Name property. This consists of the names of all assigned graphic characters, including those names which are generated algorithmically based on code point, such as CJK UNIFIED IDEOGRAPH-4E00.
- Code point labels. These are algorithmically generated labels based on code point values, used to refer to assigned characters that do not have a non-null value of the Unicode Name property, such as control characters and noncharacters, and to all unassigned code points in the Unicode codespace.
- Formal name aliases. This consists of all values listed in the data file NameAliases.txt, comprising various corrections and abbreviations for character names, including aliases for some characters which have null values of the Unicode Name property.
- Names for Unicode named character sequences.
The rules which specify how the names in the Unicode namespace for character names are constructed are spelled out in Section 4.8, Name in [Unicode]. Further conventions which apply specifically to the creation of appropriate names for Unicode named character sequences are provided in UAX34-R4 below.
The uniqueness rule for names in the Unicode namespace is specified in UAX34-R3 below.
The notation for a Unicode named character sequence consists of the general conventions for character sequences in Appendix A, Notational Conventions, of [Unicode], together with name conventions as specified in Section 4, Names. Thus a typical representation of a Unicode named character sequence would be a USI followed directly by the name of the sequence:
<U+012B, U+0300> LATIN SMALL LETTER I WITH MACRON AND GRAVE
In contexts that supply other clear means for delimitation, such as data files or tables, the bracketing and comma delimitation conventions for the sequences may be dropped, as in
012B 0300;LATIN SMALL LETTER I WITH MACRON AND GRAVE
Conformance to the Unicode Standard requires conformance to the specification in this annex. The relationship between conformance to the Unicode Standard and conformance to an individual Unicode Standard Annex (UAX) is described in more detail in Section 3.2, Conformance Requirements in [Unicode].
UAX34-C1. If a process purports to implement Unicode named character sequences, it shall use only those named character sequences defined in the file NamedSequences.txt in the Unicode Character Database.Only the named character sequences in NamedSequences.txt are named in this standard. No other Unicode character sequences are given names in this version of the Unicode Standard, although named character sequences may be added in the future. Only sequences that are in Normalization Form NFC are given names in the Unicode Standard.
Conformance to this clause should not be construed as preventing implementers from providing informal names of their choice to any entities or character sequences, as appropriate. However, such informal names are not specified in any way by this standard for use in interchange.
The use of unnamed character sequences is not affected by the specifications in this annex.
When named character sequences are first suggested for inclusion in the Unicode Standard, they may be accepted provisionally. In such cases, they are listed in the file NamedSequencesProv.txt. See [DataProv].
Character sequences and proposed names listed in NamedSequencesProv.txt are provisional only and have no other status. They become part of the standard itself only when approved for inclusion in NamedSequences.txt.
The use of a provisional list is meant to allow sufficient time for review and comment on proposed named character sequences before they are finally approved. This also enables the normative data file, NamedSequences.txt, to remain stable.
Once a Unicode named character sequence has been approved, it is stable and will not be changed in any way in future versions of the standard. This stability applies both to the name of the named character sequence and to the sequence of code points associated with the name. See [Stability] for more information on the Unicode Consortium Stability Policies.
Names of Unicode named character sequences are unique. They are part of the Unicode namespace for character names.
Names for named character sequences are constructed according to the following rules:
UAX34-R1. Only Latin capital letters A to Z, digits 0 to 9 (provided that a digit is not the first character in a word), SPACE, and HYPHEN-MINUS are used for writing the names.
This rule is intended to be the same as the rules for Unicode character names, because they share the same namespace. The rules for names are specified in more detail in Section 4.8, Name in [Unicode].
UAX34-R2. Only one name is given to each named character sequence, and each named character sequence must be unique within the Unicode namespace for character names.
UAX34-R3. Names are unique in the Unicode namespace for character names if they are different even when SPACE and medial HYPHEN-MINUS characters are ignored, and when the strings “LETTER”, “CHARACTER”, and “DIGIT” are ignored in comparison of the names.
There are two grandfathered exceptions to the general statement of this uniqueness rule. These pairs of names are explicitly specified to be distinct, for historical reasons in the development of the standard, and thus must be treated as exceptional cases by any algorithm checking for name uniqueness. One of these exceptions involves two Unicode character names:
116C HANGUL JUNGSEONG OE
1180 HANGUL JUNGSEONG O-E
The other exception involves two character name aliases:
CANCEL (character name alias for the control code U+0018)
CANCEL CHARACTER (character name alias for the control code U+0094)
The rule UAX34-R3 specifies that only medial HYPHEN-MINUS characters are ignored in comparison. The term "medial" is construed here as occurring directly after a letter (or digit) and directly before a letter (or digit) in the name. It is possible for a HYPHEN-MINUS character to occur in initial position (following a SPACE) in a subpart of a Unicode character name or in final position (preceding a SPACE). In those positions the HYPHEN-MINUS is not ignored for comparison, so the following two existing Unicode character names are distinct in the namespace:
0F68 TIBETAN LETTER A
0F60 TIBETAN LETTER -A
Although there are a few Unicode characters that have a final HYPHEN-MINUS, for example, U+0F0A TIBETAN MARK BKA- SHOG YIG MGO, currently there are no character names which contrast only by the presence or absence of a HYPHEN-MINUS in that position.
The following example shows two hypothetical names that would not be unique by application of UAX34-R3:
SARATI LETTER AA
SARATI CHARACTER AA
These two names would not be unique if the strings “LETTER” and “CHARACTER” were ignored.
UAX34-R4. Where possible, names for named character sequences are constructed by appending the names of the constituent elements together while eliding duplicate elements, and possibly introducing the words “WITH” or “AND” between elements for clarity. Should this process result in a name that already exists, the name is modified suitably to guarantee uniqueness in the namespace.
Table 3 gives some examples of names for hypothetical sequences constructed according to UAX34-R4.
Table 3. Examples of Hypothetical Sequence Names
| USI | Alternate Representation of Sequence | Name |
|---|---|---|
| <0041, 0043, 0043> | <A, B, C> | LATIN CAPITAL LETTER A B C |
| <00CA, 0046> | <AE, F> | LATIN CAPITAL LETTER AE F |
| <0058, 030A> | <X, COMBINING RING ABOVE> | LATIN CAPITAL LETTER X WITH RING ABOVE |
UAX34-R5. Where applicable, the rules from Annex L, "Character naming guidelines" in ISO/IEC 10646:2020 apply.
Note: Just as for character names, the names for sequences may be translated, with the translated names for each language being unique with respect to each other and the corresponding set of translated character names. However, translated names are not restricted to the same limited character set as the English names. Translated names may not be suitable as identifiers without modification.
A normative data file, NamedSequences.txt, is available consisting of those named character sequences defined for this version of [Unicode]. The sequences are listed in the data file in an abbreviated format. For the location of the data file, see [Data34].
In addition, a provisional data file, NamedSequencesProv.txt, is available containing sequences and names proposed for the standard but not yet approved as part of the normative list of named character sequences. For the location of the data file, see [DataProv].
The abbreviated format for named character sequences in the data files uses space delimitation of code points, without the "U+" prefix and without angle brackets. This format for code point sequences is widely shared in data files of the Unicode Character Database. The names for named character sequences are listed in a separate, semicolon-delimited field. Thus a typical entry for the data file is as follows:
TAMIL CONSONANT K; 0B95 0BCD
Implementations of Unicode named character sequences may use other formats for this data, as appropriate. The key information is the name itself and its associated code point sequence.
Ken Whistler authored the initial version and maintains the text.
Thanks to Asmus Freytag, Mark Davis and Julie Allen for comments on this annex, including earlier versions. Addison Phillips helped to maintain the text for Revisions 13 through 17.
For references for this annex, see Unicode Standard Annex #41, “Common References for Unicode Standard Annexes.”
The following summarizes modifications from the previous version of this annex.
Previous revisions can be accessed with the “Previous Version” link in the header.
© 2005–2025 Unicode, Inc. This publication is protected by copyright, and permission must be obtained from Unicode, Inc. prior to any reproduction, modification, or other use not permitted by the Terms of Use. Specifically, you may make copies of this publication and may annotate and translate it solely for personal or internal business purposes and not for public distribution, provided that any such permitted copies and modifications fully reproduce all copyright and other legal notices contained in the original. You may not make copies of or modifications to this publication for public distribution, or incorporate it in whole or in part into any product or publication without the express written permission of Unicode.
Use of all Unicode Products, including this publication, is governed by the Unicode Terms of Use. The authors, contributors, and publishers have taken care in the preparation of this publication, but make no express or implied representation or warranty of any kind and assume no responsibility or liability for errors or omissions or for consequential or incidental damages that may arise therefrom. This publication is provided “AS-IS” without charge as a convenience to users.
Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries.