|
|
| Editor | Eric Muller (emuller@adobe.com) |
| Date | 2011-10-04 |
| This Version | http://www.unicode.org/reports/tr50/tr50-1.html |
| Previous Version | n/a |
| Latest Version | http://www.unicode.org/reports/tr50/ |
| Latest Proposed Update | http://www.unicode.org/reports/tr50/proposed.html |
| Revision | 1 |
The layout of Japanese text follows different conventions than the layout of Western texts. Many of the requirements are described in the W3C Working Group Note “Requirements for Japanese Text Layout” [JLREQ]. This report describes two Unicode character properties which can be used to implement those requirements.
This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A Unicode Technical Report (UTR) contains informative material. Conformance to the Unicode Standard does not imply conformance to any UTR. Other specifications, however, are free to make normative references to a UTR.
Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this document is found in References. For the latest version of the Unicode Standard see [Unicode]. For a list of current Unicode Technical Reports see [Reports]. For more information about versions of the Unicode Standard, see [Versions].
The JLREQ document uses terms such as “Japanese” and “Western”, and focuses on Japanese typography with Western text elements thrown in.
It is our belief that Japanese and Chinese typography have enough commonality that the goal of the properties should be to handle both cases. It seems that Chinese typography is both somewhat simpler (for one thing, it does not use Hiragana and Katakana) and less codified. We expect that it is possible to handle Chinese by simply “downscaling” what is done for Japanese. However, we do not have enough information to explain this downscaling. The same goes for Korean written using the CJK ideographs. As for Korean written using Hangul - including the occasional CJK ideographs seen today -, we think it follows essentially the Western typographic methods and is therefore out of scope. Any information that would clarify the situation of the CJK locales besides Japan is very welcome.
As for the “Western” part, we similarly believe that it extends to other parts of the world as well and should really be interpreted in that way.
One difficulty for this document that needs a resolution is whether to use the same terms as JLREQ - in particular “Western” - and to gloss that we really mean something broader, or to use terms that are more easily understood at the cost of a disconnect with the JLREQ terminology.
The layout of Japanese text follows different convention than the layout of Western texts. Many of the requirements are described in the W3C Working Group Note “Requirements for Japanese Text Layout” [JLREQ]. In particular, this note explains the spacing of characters in lines: character occurences are classified, with classes such as cl-07, commas and cl-19, ideographic, and tables indexed by the classes of adjacent occurrences determine the actual spacing between those occurrences.
This report describes two Unicode character properties which can be use to implement those requirements.
The first property, East Asian Class, is a classification of the characters which eventually contributes to the determination of inter-character spacing, both in unjustified and in justified lines. For example:
Figure 1. Spacing of Characters
[Figure similar to the bottom part of Figure 64 in JLREQ]
In the first line, the character U+3001 、 IDEOGRAPHIC COMMA is classified as cl-07, commas and the following ideograph is classified as cl-19, ideographic. This particular combination results in an 1/2 em space introduced by layout between the two characters. Similarly, the classification of the middle dot and the characters surrounding them in the last line cause a 1/4 em space around the middle dot. Furthermore, those spaces can shrink or expand as needed for justification.
The second property, East Asian Orientation, determines the orientation of the characters in vertical lines, which can differ from their orientation in horizontal lines. For example:
Figure 2. Orientation of Characters
[Figure similar to Figure 25 in JLREQ, also showing the same text in horizontal lines]
The character U+306E の HIRAGANA LETTER NO stays upright in vertical lines, while the character U+0065 e LATIN SMALL LETTER E goes sideways in vertical lines.
The scope of application for the properties and algorithms described here is limited to the texts which are typeset according to Japanese rules. A Japanese word in the context of a English document would not obey the same spacing rules that it would obey in a Japanese document. Also, the issue of character orientation in vertical lines is entirely different when the text is set following, for example, English rules, and the algorithm described here is not relevant to that situation.
The title of this TR is obviously not well aligned with the scope and content. It is too broad given the paragraph above. It is also too narrow as the East Asian Class is not just for vertical text. The motivation for the inclusion of East Asian Class is that it is closely related to East Asian Orientation; one can effectively validate the proposed assignments for East Asian Orientation only in the context of the assignments of the East Asian Class property.
As in all matters of typography, the interesting unit of text is not the character, but something of the order of a grapheme cluster: it does not make sense to use a base character upright and a combining mark attached to it sideways.
It is expected that the client of the two properties defined here will select a notion of grapheme cluster, and is interested in obtaining a class and orientation for the clusters. This can be done by simply taking the property value of the first character in each cluster.
The properties and algorithms defined here are directly applicable to plain text. As a consequence, some classes listed in JLREQ do not appear here. For example, the JLREQ class cl-28 warichu opening brackets applies to occurrences of characters which are used to bracket a warichu construct (a form of inline parenthetical); however, there is no way in plain text to express a warichu construct.
When the properties and algorithms are used in rich text, it is acceptable to resolve occurrences of characters to classes not listed here. It is also acceptable to support markup that override the algorithms presented here.
The JLREQ document describes how character classes affect the spacing of character within lines, and its Appendix A seems to provide the classification of the characters. However, the situation is a bit more complicated.
First, Appendix A does not directly provide a method to classify the character occurrences, but rather provides the lists of classes in which an occurrence can be classified. For example, the character U+0041 A LATIN CAPITAL LETTER A appears in the list cl-27, Western characters, in the list cl-25, unit symbols, and in the list cl-19 ideographic character. The whole document just assumes that character occurrences have been somehow classified and is silent on how that is done.
Second, JLREQ ignores the existence and the common use in desktop computing of the fullwidth characters. The character U+FF21 A FULLWIDTH LATIN CAPITAL LETTER A is not listed anywhere in appendix A, yet in practice, it is used contrastively with U+0041 A LATIN CAPITAL LETTER A to distinguish occurrences which should be classified as cl-19 ideographic character rather than cl-27, Western characters.
Third, JLREQ restricts itself to the ISO/IEC 10646 [ISO 10646] collections 285 Basic Japanese and 286 Japanese Non Ideographics extension; of course, a solution that covers all of Unicode is needed.
To fill those gaps, this report defines a character property, and an algorithm using that property to classify character occurrences.
The property values are a subset of the classes defined in JLREQ, where a few classes have been split to facilitate implementation.
Will need to come up with short names and long names, and respect whatever constraints apply to those names.
Table 1. Property Values for the East Asian Class Property
| cl-01.1 | opening bracket, corner |
| cl-01.2 | opening bracket, round |
| cl-01.3 | opening bracket, other |
| cl-02.1 | closing bracket, corner |
| cl-02.2 | closing bracket, round |
| cl-02.3 | closing bracket, other |
| cl-03 | hyphen |
| cl-04 | dividing punctuation mark |
| cl-05 | middle dot |
| cl-06 | full-width stop |
| cl-07 | comma |
| cl-08 | inseparable character |
| cl-09 | iteration mark |
| cl-10 | prolonged sound mark |
| cl-11 | small kana |
| cl-12 | prefixed abbreviation |
| cl-13 | postfixed abbreviation |
| cl-14 | full-width ideographic space |
| cl-15 | hiragana |
| cl-16 | katakana |
| cl-19.1 | ideographic character |
| cl-19.2 | fullwidth number |
| cl-19.3 | symbol |
| cl-26 | western word space |
| cl-27 | western character |
The split of cl-01, opening bracket and cl-02, closing bracket is purely on a graphical basis. The purpose of the split is that it is sometimes desirable to use slightly different amounts of space depending on the shape of the bracket. The split of cl-19, ideographic serves a similar purpose.
Do we need a class for fixed width Western spaces? if we make them cl-27, they will get non-zero aki (space introduced by layout) next to ideographs or in math formulas.
If a character is routinely considered as an integral part of the Japanese writing system, it is assigned to one of the classes cl-01..cl-19. This is the case for characters in ISO/IEC 10646 collections 285 Basic Japanese and 286 Japanese Non Ideographics extension, except that Basic Latin characters are replaced by their companion character from the Halwidth and Fullwidth forms block. It is also the case for characters outside those collections which clearly are part of a set where a large part of the set is in the collections; for example, JLREQ includes U+2032 ' PRIME and U+2033 ″ DOUBLE PRIME in class cl-13; it is only natural to treat U+2034 ‴ TRIPLE PRIME and U+2057 ⁗ QUADRUPLE PRIME in the same way.
Characters which are more symbolic than alphabetic are assigned to cl-19.3, because they can function typographically as ideographs.
Remaining characters are classified in cl-26 or cl-27.
The largest use of PUA code points in Japanese texts is for idegraphs, therefore PUA code points are assigned the class cl-19.1.
Generally, reserved code points should be assigned the class most likely for their intended future assignment, to maximize forward compatibility. For the ideographic block of the SMP, planes 2 and 3, the class is cl-19.1. For the blocks of symbols, the class is cl-19.3. Other reserved code points are classified cl-27.
The property is not relevant to format, control, surrogate and noncharacter code points.
Because of the restriction of our algorithm to plain text, and given that actual usage of fullwidth characters, it turns out that one can simply use the property value of a character as the class to assign to all occurrences of that character. In other words, the algorithm is a simple lookup of the property value.
There is actually one character for which a contextual determination would be useful and reliable: U+00AE ® REGISTERED SIGN, which can occur both following terms in kanji/kana and following terms in Latin. An occurrence of ® should be assigned the same class as the character it follows. Others? Enough to warrant the complexity of contextual rules?
There are other cases where the character is used routinely in both Japanese and Western contexts: the quotes are a good example. While contextual determination would be useful, it's probably the case that it's not going to be reliable.
In vertical texts, most characters are presented either upright or sideways.
A few characters have a different appearance altogether. This is for example the case for square katakana symbols, which have two to four component kanas arranged so that that they form two lines; the two lines are stacked horizontally in horizontal text, and vertically in vertical text. A complete chart showing representative glyphs for both orientations is provided below.
The possible property values are given in table 2.
Table 2. Property Values for the East Asian Orientation Property
| U | characters that are displayed upright |
| S | characters that are displayed sideways |
| SB | brackets displayed sideways |
| T | characters which are not just upright or sideways, but require a different glyph |
| TK | small kanas, that are displayed upright and shifted |
The property values SB and TK are meant to ensure some level of compatibility with existing fonts.
The SB property is conceptually a subclass of S. It captures the common practice in fonts to actually handle those characters as if they were transformed.
The TK property is conceptually a subclass of T, as the characters are transformed; it captures the fact the transformation is a small shift which, while desirable, is not critical to the reading of the text.
Do we need TK at all?
Characters with an East Asian Class cl-27 all have the orientation S.
Characters with the East Asian Class cl-11 are exactly those with the orientation TK.
Characters with the East Asian Classes cl-01 or cl-02 are exactly those with orientation SB.
Characters with the East Asian Class cl-19 all have orientation U.
Table 3 provides representative glyphs for the horizontal and vertical appearance of characters with the property value T.
Add glyphs for all the entries: 301F, 332C, FF61, FF64, 1F200, 1F201, halfwidth small kanas. Some glyphs (2018, 2019) may not be correct.
Table 3. Glyph Changes for Vertical Orientation
| character | H | V | comment |
| U+2018 LEFT SINGLE QUOTATION MARK |

|

|
|
| U+2019 RIGHT SINGLE QUOTATION MARK |

|

|
|
| U+3001 IDEOGRAPHIC COMMA |

|

|
|
| U+3002 IDEOGRAPHIC STOP |

|

|
|
| U+301C WAVE DASH |

|

|
mirroring, not just rotation |
| U+301D REVERSED DOUBLE PRIME QUOTATION MARK |

|

|
|
| U+301E DOUBLE PRIME QUOTATION MARK |

|

|
|
| U+301F LOW DOUBLE PRIME QUOTATION MARK |

|

|
|
| U+30FC KATAKANA-HIRAGANA PROLONGED SOUND MARK |

|
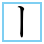
|
mirroring, not just rotation |
| U+3041 HIRAGANA LETTER SMALL A |

|

|
|
| U+3043 HIRAGANA LETTER SMALL I |

|

|
|
| U+3045 HIRAGANA LETTER SMALL U |

|

|
|
| U+3047 HIRAGANA LETTER SMALL E |

|

|
|
| U+3049 HIRAGANA LETTER SMALL O |

|

|
|
| U+3063 HIRAGANA LETTER SMALL TU |
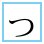
|

|
|
| U+3083 HIRAGANA LETTER SMALL YA |

|

|
|
| U+3085 HIRAGANA LETTER SMALL YU |
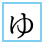
|

|
|
| U+3087 HIRAGANA LETTER SMALL YO |

|

|
|
| U+308E HIRAGANA LETTER SMALL WA |

|

|
|
| U+3095 HIRAGANA LETTER SMALL KA |

|

|
|
| U+3096 HIRAGANA LETTER SMALL KE |

|
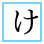
|
|
| U+30A1 KATAKANA LETTER SMALL A |

|

|
|
| U+30A3 KATAKANA LETTER SMALL I |

|

|
|
| U+30A5 KATAKANA LETTER SMALL U |

|

|
|
| U+30A7 KATAKANA LETTER SMALL E |

|

|
|
| U+30A9 KATAKANA LETTER SMALL O |

|

|
|
| U+30C3 KATAKANA LETTER SMALL TU |

|

|
|
| U+30E3 KATAKANA LETTER SMALL YA |

|

|
|
| U+30E5 KATAKANA LETTER SMALL YU |

|

|
|
| U+30E7 KATAKANA LETTER SMALL YO |

|

|
|
| U+30EE KATAKANA LETTER SMALL WA |

|

|
|
| U+30F5 KATAKANA LETTER SMALL KA |

|

|
|
| U+30F6 KATAKANA LETTER SMALL KE |

|

|
|
| U+31F0 KATAKANA LETTER SMALL KU |

|

|
|
| U+31F1 KATAKANA LETTER SMALL SI |

|

|
|
| U+31F2 KATAKANA LETTER SMALL SU |

|

|
|
| U+31F3 KATAKANA LETTER SMALL TO |
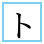
|

|
|
| U+31F4 KATAKANA LETTER SMALL NU |

|

|
|
| U+31F5 KATAKANA LETTER SMALL HA |

|

|
|
| U+31F6 KATAKANA LETTER SMALL HI |

|

|
|
| U+31F7 KATAKANA LETTER SMALL HU |

|

|
|
| U+31F8 KATAKANA LETTER SMALL HE |

|

|
|
| U+31F9 KATAKANA LETTER SMALL HO |

|

|
|
| U+31FA KATAKANA LETTER SMALL MU |

|

|
|
| U+31FB KATAKANA LETTER SMALL RA |

|

|
|
| U+31FC KATAKANA LETTER SMALL RI |

|

|
|
| U+31FD KATAKANA LETTER SMALL RU |

|

|
|
| U+31FE KATAKANA LETTER SMALL RE |

|

|
|
| U+31FF KATAKANA LETTER SMALL RO |

|

|
|
| U+3300 SQUARE APAATO |

|

|
|
| U+3301 SQUARE ARUHUA |

|

|
|
| U+3302 SQUARE ANPEA |

|

|
|
| U+3303 SQUARE AARU |

|

|
|
| U+3304 SQUARE ININGU |

|

|
|
| U+3305 SQUARE INTI |

|

|
|
| U+3306 SQUARE UON |

|

|
|
| U+3307 SQUARE ESUKUUDO |

|

|
|
| U+3308 SQUARE EEKAA |

|

|
|
| U+3309 SQUARE ONSU |

|

|
|
| U+330A SQUARE OOMU |

|
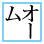
|
|
| U+330B SQUARE KAIRI |

|

|
|
| U+330C SQUARE KARATTO |

|

|
|
| U+330D SQUARE KARORII |

|

|
|
| U+330E SQUARE GARON |

|

|
|
| U+330F SQUARE GANMA |

|

|
|
| U+3310 SQUARE GIGA |

|

|
|
| U+3311 SQUARE GINII |

|

|
|
| U+3312 SQUARE KYURII |

|

|
|
| U+3313 SQUARE GIRUDAA |

|

|
|
| U+3314 SQUARE KIRO |

|

|
|
| U+3315 SQUARE KIROGURAMU |

|

|
|
| U+3316 SQUARE KIROMEETORU |
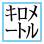
|

|
|
| U+3317 SQUARE KIROWATTO |

|

|
|
| U+3318 SQUARE GURAMU |

|

|
|
| U+3319 SQUARE GURAMUTON |

|

|
|
| U+331A SQUARE KURUZEIRO |

|

|
|
| U+331B SQUARE KUROONE |

|

|
|
| U+331C SQUARE KEESU |

|

|
|
| U+331D SQUARE KORUNA |

|

|
|
| U+331E SQUARE KOOPO |

|

|
|
| U+331F SQUARE SAIKURU |

|

|
|
| U+3320 SQUARE SANTIIMU |

|

|
|
| U+3321 SQUARE SIRINGU |

|

|
|
| U+3322 SQUARE SENTI |

|

|
|
| U+3323 SQUARE SENTO |

|

|
|
| U+3324 SQUARE DAASU |

|

|
|
| U+3325 SQUARE DESI |

|

|
|
| U+3326 SQUARE DORU |

|

|
|
| U+3327 SQUARE TON |

|

|
|
| U+3328 SQUARE NANO |

|

|
|
| U+3329 SQUARE NOTTO |

|

|
|
| U+332A SQUARE HAITU |

|

|
|
| U+332B SQUARE PAASENTO |

|

|
|
| U+332C SQUARE PAATU |

|

|
|
| U+332D SQUARE BAARERU |

|
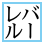
|
|
| U+332E SQUARE PIASUTORU |

|

|
|
| U+332F SQUARE PIKURU |

|

|
|
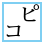
| U+3330 SQUARE PIKO |

|
|
|
| U+3331 SQUARE BIRU |

|

|
|
| U+3332 SQUARE HUARADDO |

|

|
|
| U+3333 SQUARE HUIITO |

|

|
|
| U+3334 SQUARE BUSSYERU |

|

|
|
| U+3335 SQUARE HURAN |

|

|
|
| U+3336 SQUARE HEKUTAARU |

|

|
|
| U+3337 SQUARE PESO |

|

|
|
| U+3338 SQUARE PENIHI |

|

|
|
| U+3339 SQUARE HERUTU |

|

|
|
| U+333A SQUARE PENSU |

|

|
|
| U+333B SQUARE PEEZI |

|

|
|
| U+333C SQUARE BEETA |

|

|
|
| U+333D SQUARE POINTO |

|

|
|
| U+333E SQUARE BORUTO |

|

|
|
| U+333F SQUARE HON |

|

|
|
| U+3340 SQUARE PONDO |

|

|
|
| U+3341 SQUARE HOORU |

|

|
|
| U+3342 SQUARE HOON |

|

|
|
| U+3343 SQUARE MAIKURO |

|

|
|
| U+3344 SQUARE MAIRU |

|

|
|
| U+3345 SQUARE MAHHA |

|

|
|
| U+3346 SQUARE MARUKU |

|

|
|
| U+3347 SQUARE MANSYON |

|

|
|
| U+3348 SQUARE MIKURON |

|

|
|
| U+3349 SQUARE MIRI |

|

|
|
| U+334A SQUARE MIRIBAARU |

|

|
|
| U+334B SQUARE MEGA |

|

|
|
| U+334C SQUARE MEGATON |

|

|
|
| U+334D SQUARE MEETORU |

|

|
|
| U+334E SQUARE YAADO |

|

|
|
| U+334F SQUARE YAARU |

|

|
|
| U+3350 SQUARE YUAN |

|

|
|
| U+3351 SQUARE RITTORU |

|

|
|
| U+3352 SQUARE RIRA |

|

|
|
| U+3353 SQUARE RUPII |

|

|
|
| U+3354 SQUARE RUUBURU |

|

|
|
| U+3355 SQUARE REMU |

|

|
|
| U+3356 SQUARE RENTOGEN |

|

|
|
| U+3357 SQUARE WATTO |

|

|
|
| U+337B SQUARE ERA NAME HEISEI |

|

|
|
| U+337C SQUARE ERA NAME SYOUWA |

|

|
|
| U+337D SQUARE ERA NAME TAISYOU |

|

|
|
| U+337E SQUARE ERA NAME MEIZI |

|

|
|
| U+337F SQUARE CORPORATION |

|

|
|
| U+FF61 HALFWIDTH IDEOGRAPHIC FULL STOP |

|

|
|
| U+FF64 HALFWIDTH IDEOGRAPHIC COMMA |

|

|
|
| U+FF67 HALFWIDTH KATAKANA LETTER SMALL A |

|

|
|
| U+FF68 HALFWIDTH KATAKANA LETTER SMALL I |

|

|
|
| U+FF69 HALFWIDTH KATAKANA LETTER SMALL U |

|

|
|
| U+FF6A HALFWIDTH KATAKANA LETTER SMALL E |

|

|
|
| U+FF6B HALFWIDTH KATAKANA LETTER SMALL O |

|

|
|
| U+FF6C HALFWIDTH KATAKANA LETTER SMALL YA |

|

|
|
| U+FF6D HALFWIDTH KATAKANA LETTER SMALL YU |

|

|
|
| U+FF6E HALFWIDTH KATAKANA LETTER SMALL YO |

|

|
|
| U+FF6F HALFWIDTH KATAKANA LETTER SMALL TU |

|

|
|
| U+1F200 SQUARE HIRAGANA HOKA |

|

|
|
| U+1F201 SQUARE KATAKAN KOKO |

|

|
The data file, in UCD syntax: ealayout.txt.
To help during the review, the following data files are available as well:
U+3030 〰 WAVY DASH; should it be rotated/mirrored like U+301C 〜 WAVE DASH?
U+2016 ‖ DOUBLE VERTICAL LINE; JRLEQ classifies this character as cl-19 ideographic; typically, this is a clue that it is upright; also, JIS 0213:2000 does not give a vertical variant. On the other hand, it seems that 'vert' often presents it sideways. Which is right? Could it be that font vendors have been influenced by U+30A0 ゠ KATAKANA-HIRAGANA DOUBLE HYPHEN?
Thanks to the reviewers: Julie Allen, Ken Lunde, Nat McCully, Ken Whistler, Taro Yamamoto.
| [JLREQ] | Requirements for Japanese Text layout, W3C Working Group Note 4 June 2009 |
| [Errata] | Updates and Errata http://www.unicode.org/errata |
| [Feedback] |
http://www.unicode.org/reporting.html
For reporting errors and requesting information online. |
| [ISO 10646] | International Organization for Standardization. Information Technology—Universal Multiple-Octet Coded Character Set (UCS). (ISO/IEC 10646:2011). For availability, see: http://www/iso.org |
| [Reports] | Unicode Technical Reports http://www.unicode.org/reports/ For information on the status and development process for technical reports, and for a list of technical reports. |
| [Unicode] |
The Unicode Standard, Version 6.1.0,
defined by: The Unicode Standard, Version
6.1.0 (Mountain View, CA: The Unicode Consortium, 2012. ISBN 978-1-936213-02-3) http://www.unicode.org/versions/Unicode6.1.0 |
| [Versions] | Versions of the Unicode Standard http://www.unicode.org/versions/ For details on the precise contents of each version of the Unicode Standard, and how to cite them. |
This section indicates the changes introduced by each revision.
Revision 1
(draft 1) First working draft.
Copyright © 2011 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report. The Unicode Terms of Use apply.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.
{kind=link}
{kind=link}