Fonts and Keyboards
Fonts and Unicode
Q: Is Unicode a font?
Unicode is not a font, but most fonts are built on the specifications of the Unicode Standard. The Unicode Standard defines characters, assigning a unique number to each character. Fonts use this number to refer to the character. To put it another way, you access the characters in Unicode via fonts. For more information, see Basic Questions.
Q: Can I use Unicode characters without asking for permission from the Unicode Consortium?
You don't need any special licensing or permission to use Unicode characters. This includes using them in products, in data, or in any other context. While the text of the Unicode Standard is copyrighted, this does not affect your use of Unicode to support the characters or writing systems.
Q: Am I allowed to extract glyphs or fonts from the Unicode code charts?
No. You may not extract the glyphs from the PDF code charts and use them in products. The fonts used in the PDF code charts on our website are licensed by their owners for chart usage only, and they may not be re-used without permission of the font suppliers. Please see https://www.unicode.org/charts/fonts.html for a list of suppliers.
Q: I'm a software developer. Is there anything else I need to know about terms of use before using Unicode characters?
Before using any part of the standard, you should read all of our documentation and the Unicode Terms of Use. If you are interested in using the code charts, please see Character Code Charts Help and Links and the terms of use found on the first page of each of the code chart files.
Q: How can I get glyphs for the character I need?
Fonts are available for a wide range of scripts on most platforms. You can also purchase the license for a font designed by someone else, or you can search the web for the many fonts which have been placed in the public domain or which have free licenses.
With the right tools, you can design your own fonts. For help with font resources, please see Fonts. Or you can contact the font vendors who contributed to the production of our code charts, listed on our font supplier page: Font Contributors Acknowledgements.
Q: Where can I find out which fonts support which scripts and characters?
The Unicode Consortium does not have or maintain any information about the character coverage of publicly available or commercial font offerings. However, such information can be found on the web. Particularly helpful, for example, is Richard Ishida's list of fonts distributed with Windows and Mac OS X, grouped by scripts.
distributed with Windows and Mac OS X, grouped by scripts.
Q: How many fonts are used in publication of the Unicode Standard?
Currently, several hundred different fonts are used to publish the code charts and the figures associated with the Unicode Standard. The overwhelming majority of these fonts are specially tailored for this purpose and have been donated to the Unicode Consortium with a restricted license for use only in documenting the standard. See the Font Acknowledgements.
Q: What is a Unicode-conformant font?
A font is never used in isolation: it is one of the components used in text rendering systems. Therefore, it is not strictly meaningful to ask if a font is Unicode-conformant; this question is more pertinent for the rendering system as a whole.
Nevertheless, most rendering systems involve some kind of mapping from characters to glyphs, stored in fonts. In sfnt-based fonts, such as TrueType, OpenType and Graphite fonts, default glyph mappings are stored in the 'cmap' table; additional tables may substitute alternate glyphs based on context. A Unicode-conformant font can be defined as a font which contains a mapping from Unicode characters and that maps characters to glyphs in a way that is consistent with character semantics defined in the Unicode Standard.
For example, a font that includes a character-to-glyph mapping based only on the JIS (Japanese Industrial Standard) character encoding would not be Unicode compliant. (Note, however, that such a font potentially may be used within a text rendering system that can handle conversions between legacy encodings and Unicode to display text in a Unicode-conformant way.) For another example, a TrueType font that includes a Windows Unicode 'cmap' table but that maps characters in the Latin-1 block to glyphs for Cyrillic characters is not a Unicode-conformant font.
The best place to find information about Unicode-compliant fonts is our Unicode Resources fonts page. [EM] & [DA]
Q: Does the Unicode Consortium endorse Unicode conformant fonts?
The Unicode Consortium does not review or evaluate fonts for their compliance to the Unicode Standard. See also the answer to "Where can I find out which fonts support which scripts and characters?".
Q: How can I make an OpenType font?
The following page contains pointers for creating OpenType fonts: Unicode Resources fonts page.
Q: How can I make AAT fonts?
A full AAT specification is available at https://developer.apple.com/fonts/TrueType-Reference-Manual/. Apple makes its tools for developing AAT fonts available to the public. You will need an Apple ID and a free developer account to download them. https://developer.apple.com/fonts/ contains a link to the download page. The downloaded package includes a full set of command-line tools as well as documentation and a detailed tutorial for using them. [JJ]
Q: What is a Graphite font?
Graphite is a technology that can be used to create “smart fonts” capable of displaying writing systems with various complex behaviors. A smart font contains not only letter shapes but also additional instructions indicating how to combine and position the letters in complex ways. See https://graphite.sil.org/.
Q: What factors influence how I can display characters in Java applications?
Displaying Unicode correctly in Java is dependent on 3 factors:
- physical fonts
- composite fonts in the font.properties file
- Swing and AWT components.
Fonts store glyphs. You must have an appropriate font containing the glyphs for the character that you want to display. You can use a physical font name or a virtual “composite” font name in your text components.
Composite fonts map a logical font name to physical fonts on your system. When you set the font on a text component, you can use either a physical font name or a composite font name. If you use a composite font name, you must make sure that the composite font is correctly configured in your font.properties file. This file maps a composite or logical font name to one or more physical fonts. At least one of the physical fonts in the mapping must contain the appropriate glyphs for the characters you want to display.
AWT components first convert the Unicode characters to the host's native character set encoding. If the target character set does not have the needed Unicode character, a substitute character is often used to represent the original character. AWT components are not typically flexible enough to display wide ranges of multilingual text because of their dependence on a single, rather limited charset or codepage.
On the other hand, Swing components do not suffer from the same limitations as AWT components. Because Swing components do not convert a Unicode character to the host's native charset or codepage, these components can typically display a wide range of multilingual text.
Glyph Variations
Q: There seems to be a lot of variation in the glyphs for some characters. As a font maker, I want to know the acceptable range of glyphs for some common cases. Where can I go?
One place to start is the Microsoft Typography web site. Some of the questions and answers below may also give you an idea of the range of allowable variations. If you scroll down, there is a table of variations to which several of these questions refer.
Q: Does the Unicode Standard prescribe the glyph shape for each character?
Characters are encoded based on their identity, which in most cases allows for a range of font-specific shapes conventionally associated with that identity. See for example row 9 of the accompanying table (below) showing two glyphs for “numero”. Sometimes, the shape depends on the posture of the font. For example, the letters “a” and “g” as shown in rows 11 and 12 of the table. Common variations may be seen in italic and sans-serif fonts. The “y with hook” letter U+01B3, U+01B4 has two common variations as shown in row 13 of the table. Some fonts show the curl on one side for capitals and the other for small letters; some fonts have the curls on the same side.
There are cases where a specific appearance for a letter has a particular meaning different from the garden variety instances of the same letter. When characters are encoded for such uses, the expectation is that their appearance in fonts should be implemented with glyphs that serve to express the distinction.
Q: What is the status of the glyphs listed in the standard?
The glyphs used in the code charts are chosen to help identify the character that is encoded at that location, and to help users make sure they pick the correct character code whenever there is a possible confusion. This does not mean that these glyphs are in any way the preferred representation. There are several examples of other acceptable glyphs in the table below, such as rows 9 and 10. The upsilon sometimes has straight arms, sometimes curly arms, depending on font design.
Q: Are diacritical marks encoded by shape, position or meaning?
Because diacritical marks are encoded with their own character code when text is decomposed, there is a strong preference to encode diacritical marks based on meaning, and allowing the exact shape and position to change depending on the conventions of language or orthography. In some cases, diacritical marks assume shapes that look like a different diacritical mark in some orthography or take different shapes for upper and lowercase. If you look at the variations on lower-case “g” in the table (row 1), you can see examples of possible variations.
Q: Why is there a separate encoding for certain letters with commas below vs. cedillas?
Some languages preferentially use commas to cedillas, or vice versa, as in rows 2 and 3 of the table below. Many times, these are encoded by one pre-composed character in the standard, which may be displayed with language-dependent glyphs. However, for compatibility and legacy reasons, some such variations are exceptionally encoded as separate characters.
Q: Are haceks and apostrophes variants of each other? And what is a caron anyway?
An apostrophe above and to the right is a common variation for the hacek (caron) on some letters such as “d” and “t”, as shown in rows 4, 5, 6, 7 of the table. (“Caron” is just standardese for “hacek”, and there is another FAQ about that word.)
Q: What about Han characters? Are the CJK glyphs in the Unicode Standard normative?
This is a deep and complicated subject, and there is a separate FAQ page on Han and CJK issues. There are some variations in Han characters that are merely stylistic, others that are encoded. For example, the ideograph for “bone” in row 14 of the table has two common variants.
Strictly speaking, the identity of a character in Unihan is not established by the representative glyph appearing in the Unicode code charts, but by its source mappings in the Unihan Database. Designers interested in creating a CJK font for any given locale must consider the Unicode code chart glyph in the context of the Unihan Database mappings relevant to their specific locale.
The representative unified glyph appearing in a Unihan code chart is determined in the encoding process, based on the submitted source glyphs and their associated mappings. (Recent versions of the code charts show multiple, locale-specific representative glyphs). The characteristic features of a representative unified glyph such as its stroke types, stroke count, and certain other features make it distinct in the encoding model used in the encoding process. The source glyphs behind the unified glyph, that is, the bitmaps (derivative of specific print sources) contributed by IRG members may or may not agree with the unified glyph in terms of stroke count, stroke types, fine positioning of strokes and components, and in fact source glyphs often do not harmonize with each other stylistically at all.
CJK unification is possible (and largely practical) because abstract distinctive features (and assemblages of distinctive features) for Han ideographs are seen as common across locales (sources). This does not mean that all features are shared or distinctive in all locales. Font developers may decide to treat some Unihan distinctions as non-distinctive for their specific purpose. Just as developers must determine (on the basis of the Unihan Database mappings) which code points are suitable for inclusion in their typefaces, so too they are free to choose something like one of the explicitly unified glyphs for their typeface (on the basis of the relevant source mappings), or something else altogether (hopefully within reason).
Q: Where can I read more about the topic of glyph variations?
Glyph variations for the Latin script are discussed in Section 7.1, Latin of The Unicode Standard. Glyph variations for the Han script are discussed in Section 18.1, Han. For character/glyph relations, see also UTR #17: Unicode Character Encoding Model. Glyph variations in mathematical context are discussed in UTR #25: Unicode Support for Mathematics. See also the Variation Sequences FAQ.
Q: What are some examples of the possible range of glyph variations?
See the table below. Several questions above refer to the glyphs depicted in the table.
Examples of Glyph Variations
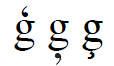
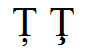

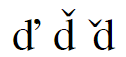

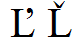
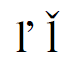
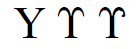

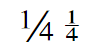
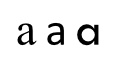

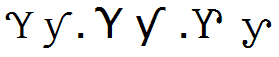

Character Input by Hexadecimal Code
Q: How can I input any Unicode character if I know its hexadecimal code?
Some platforms have methods of hexadecimal entry; others have only decimal entry.
- Microsoft Windows
- In some applications such as Microsoft Word or Outlook, Unicode characters can be inserted by typing the hexadecimal value of the character and pressing Alt + x. In some versions, such as the French and German editions of Microsoft Word, the key combination is Alt + c. Many Windows applications support a similar mechanism with variations in the key sequence. Sometimes repeating the key sequence toggles between character code and hexadecimal code. Sometimes a Shift key or some other alternation to the key sequence is needed to get back to hex codes. Note, if the hex code you want to convert is preceded by one or more hexadecimal digits, you will need to “select” the code so that the preceding hexadecimal characters aren't included in the code.
- macOS (Apple Mac computers)
- To input Unicode characters by their hexadecimal code directly, first add the "Unicode Hex Input" keyboard under "Input Sources" in the Keyboard settings. Then, switch to that input method, hold down the ⌥ Option key, type the hexadecimal code of the character, and the character will be inserted. Note that this input method does not support inserting characters with more than 4 hexadecimal digits (U+10000 and above).
- Linux
- On GNOME and other GTK desktop environments, Unicode characters can be inserted by first pressing Ctrl + Shift + u, releasing it, typing the hexadecimal code, and pressing Space or Enter. At this time, KDE and other Qt desktop environments do not have an equivalent function.
- Mobile
- There are no official ways to input Unicode characters by hexadecimal code on iOS or Android, but there are several third-party keyboards available on their respective app marketplaces that offer the functionality.
Q: How can I enter a character when I know what it looks like?
Most operating systems come with a character selection application that allows you to input Unicode characters by selecting them from a list. Some applications support an "Insert Symbol" that is a light weight version of the same.
On Microsoft Windows this is called "Character Map" and can be opened like any other application.
On Apple macOS, it is called "Character Viewer" and can be accessed first opening the "Emoji & Symbols" dialog by choosing Edit > Emoji & Symbols, or by selecting "Show Emoji & Symbols" from the Input menu. Then, the Character Viewer can be accessed by expanding the dialog using the icon on the top right.
On Linux, GNOME comes with GNOME Character Map, and KDE comes with KCharSelect, which both provide similar functionality.
There are no similar applications that ship with iOS or Android, but there are several third-party applications available on their respective app marketplaces that offer the functionality.
Inputting Chinese Characters
Q: How are Chinese characters input?
All keyboards, no matter what symbols appear on the keycaps themselves, convert individual key presses into intermediate electronic signals that are then interpreted by low-level layers of software into sequences of input characters (or commands). Characters themselves are not hard-wired into keys.
Because the set of Chinese characters is so huge, it is highly impractical (and for any practical keyboard, impossible) to try to map each character to a single key. Therefore, all keyboards for inputting Chinese characters make use of schemes involving sequences of key presses to select specific Chinese characters or sequences of characters from the available repertoire supported. [RC]
Q: Is there a common name for these schemes to input Chinese characters?
Yes, they are generally referred to as Input Method Editors, or IMEs for short. Sometimes they are called simply “input methods.” Depending on what particular method they use for enabling the use to input their choices and select particular characters, IMEs often have particular names. They may also differ in strategy between inputting Chinese characters for the Chinese language and Chinese characters for the Japanese language (kanji), based on different linguistic expectations of the users and differences in the particular repertoire of characters that needs to be supported. [RC]
Q: Are IMEs part of the operating system?
When an operating system is prepared for use in East Asia, it always has one or more IMEs built in, to make it practical for users to input their characters. However, applications sometimes provide their own input methods as well, which may provide alternative input strategies or which may be better suited to that particular application. Provision of a well-designed IME in an East Asian market may be a competitive advantage for a particular application in that market. [RC]
Q: What kinds of IMEs are used for Chinese?
The most commonly seen input methods for Chinese make use of some kind of romanization. Others make use of CJK character component and stroke-based methods. Some may also allow direct input of hexadecimal character values. In addition to keyboard-based input methods, there are also handwriting-recognition systems that take input from a stylus, voice-recognition systems taking spoken input, and optical character recognition systems taking input from scans of handwritten or printed pages. [RC]
Q: How does a romanization IME work for Chinese?
The most commonly used romanization in use today is 漢語拼音 Hànyǔ Pīnyīn, or just “pinyin” for short. Pinyin represents each syllable of Beijing Chinese (PRC Modern Standard) by means of a combination of Latin characters, optionally modified by tone marks. The tone marks consist either of numbers at the end of the syllable or diacritics placed on the main vowel.
A given syllable as romanized in pinyin may correspond to one or — more often — to many particular Chinese characters. The user types in the pinyin syllable as a sequence of Latin characters (and the tone indicators). When the syllable is to be converted to the correct Chinese character for input, the input method presents the user with a palette of characters having that pronunciation, from which to make the appropriate selection by keyboard (or mouse) action.
Single syllable pronunciations involve lots of homophones in Chinese (and even more so in Japanese), but disyllabic word combinations are much less ambiguous. So if the input method supports disyllabic or polysyllabic input, storing up romanized input for more than one syllable at a time before it is converted to Chinese characters, then the number of possible choices corresponding to that pronunciation is greatly reduced, and input can often be made much more efficient.
IMEs may also make use of statistical information, to increase the speed of input by sorting choices so that the more common or likely ones appear at the beginning of the selection lists. [RC]
Q: How do component- and stroke-based input methods work?
IMEs based on components and strokes work by using the shape of a character, rather than romanization of its pronunciation. Users learn keys or key combinations for basic strokes and common component chunks of Chinese characters, or choose strokes and/or components by clicking on items in a palette.
Once the user has made a selection of character components, the IME seeks to identify characters in the repertoire matching those criteria. In this respect, component-based input is rather like a regular expression search, which can be as loose or as tight as the IME allows. Component and stroke input methods share, in some regards, the idea of a syntax for a systematic graphic description of Chinese characters, similar to that of Unicode Ideographic Description Characters. (See Section 18.2, Ideographic Description in The Unicode Standard.)
However, practical input methods are optimized to make it easier for the user to memorize the required key sequences and to minimize the number of key presses needed for inputting particular characters. For more information on component-based input and the descriptions of Chinese characters upon which they are based, see Wenlin's CDL XML application for describing Han (CJKV) characters. [RC]
Q: How about hexadecimal input of Chinese characters?
Some applications permit direct input of Chinese characters by means of the Unicode hexadecimal code point for that character. This approach isn't particularly efficient, but it works as a fallback when an input method doesn't support a particular character or when a user is unfamiliar with that IME. The user can always look up the Unicode code point for a character in the radical/stroke index to the Unicode code charts, and then simply input the hexadecimal sequence by whatever convention the IME supports. See also this entry in the present FAQ. [RC]
Q: Where can I find out more about Chinese input methods?
For general information, try searching for “input method editor”. For information about specific vendor's IMEs for particular languages, you can search on “Chinese input method” or “Japanese input method”. [RC]