- Previous message: Danny Piccirillo: "Fwd: Copyleft Symbol"
- Next in thread: Shriramana Sharma: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Reply: Shriramana Sharma: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Reply: Peter Constable: "RE: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Maybe reply: Kenneth Whistler: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
Hello list.
The visarga, jihvamuliya and upadhmaniya are three different phones
(sounds) in Sanskrit, BOTH Vedic and Classical. All three are voiceless
fricatives - glottal, velar and bilabial, respectively. Often the latter
two are analysed as being allophones of the first. In any case, the
existence of all three as mutally distinct sounds in contemporary usage
of both Vedic and Classical Sanskrit is beyond question. Thus these are
sounds in their own right, and they are not like "anunasika" (nasality)
which is not a sound in its own right but merely a quality of other sounds.
In Indic scripts, the visarga is usually written by two dots, whose
actual realization varies slightly from script to script.
[The Tamil Aytha Ezhuttu (ஆய்த எழுத்து) has been named Visarga for purpose
of Unicode encoding, but the term visarga is not native to Tamil's
grammar or phonology unlike in the other Indian languages and its
function is also distinct from that of the visarga in other Indian
languages. So I will not talk about it here.]
The "ardhavisarga" is a sign (not a sound) written by two cup-like
curves, with one cup open upwards and the other open downwards. It is
used in Sanskrit texts to denote the jihvamuliya and upadhmaniya. Though
it has been labeled a "Vedic" character and placed in the "Vedic
Extensions block", its usage is not limited to Vedic Sanskrit, though it
is limited to Sanskrit. (The Kannada signs for jihvamuliya and
upadhmaniya are also used only for Sanskrit and not native Kannada.)
The ardhavisarga is able to denote both the above sounds unambiguously
from context because the jihvamuliya occurs only before [k] or [kh] and
the upadhmaniya occurs only before [p] or [ph]. Sanskrit Grammatical
rules (8.3.37, see http://wikisource.org/wiki/Aṣṭādhyāyī_8) say that the
visarga *may* become a jihvamuliya or upadhmaniya *or not*, so there is
a potential contrast between the visarga and ardhavisarga signs and
hence a need to separately encode visarga and ardhavisarga signs in Unicode.
Now with this background information, let us proceed.
To my mind, a combining mark is *usually* (though not always) something
that qualifies what is represented by a base character. Thus, if अ
represents a vowel, the anunasika sign added to it qualified it and says
"this sound is nasal" -> अँ. When a character does not qualify the sound
represented by a preceding character but indicates a separate sound, it
should not be considered a combining mark.
Therefore, since the visarga is a separate phoneme in its own right, and
does not "qualify" the preceding vowel in any way, I do not believe the
visarga sign can be classified as a combining mark, though it is encoded
in all the Indic script blocks (including Sinhala!) as Mc.
I suspect that the visarga is considered a combining mark only because
of the long-standing Indian tradition of appending aṃ and aḥ to the list
of vowels. I will not pass judgment on the appropriateness of such a
tradition here. I only point out that this causes the visarga sign to be
considered as a combining mark (just like the marks for the other
vowels), and by analogy, the ardhavisarga has also been considered a
combining mark and hence 1CF2 is given category Mc.
Now it may be asked -- what is your problem with giving visarga or
ardhavisarga the category of Mc? After all, you get the glyph position
correctly, to the right of the base character, so why not label it Mc?
My answer is in the attachment. In some Vedic texts, like in the Sama
Vedic text shown in the attachment, the visarga is visibly displaced
from the base character. I ask you to consider how the text in the
attached image will be properly encoded with the current classification
as Mc.
This is NOT a problem with rendering systems. Recently it was remarked
on this list that the problem with displaying cases like आँः or आ॑ः
properly is with the renderer, not with the encoding. Though that remark
may be accepted given the reasonable expectation that the renderer
should support the addition of more than one combining marks to a single
base character, it cannot be said so in the present case of the attached
text:
क्रयाहुताऽ२३४५ः
How can the maker of a rendering engine be expected to foresee this need
for a visarga to be placed after a *digit*? Normally combining marks are
used only for letters, so renderers will support only that.
Creators of rendering engines cannot be expected to be Vedic scholars.
It is up to those who encode these characters to research properly the
behaviour of these characters and set the Unicode properties of the
characters such that all valid renderings should be made possible.
Further, keeping the visarga as Mc and applying it to digits is
semantically meaningless. If at all the visarga is to be considered a
combining mark, as for example
http://en.wikipedia.org/wiki/Malayalam_script#Other_symbols which says:
"adds voiceless breath after vowel", it semantically attaches only to a
vowel (whether independent, or inherent in a consonant or displayed by a
vowel sign). How can it meaningfully be attached to a digit? This is
another reason why the visarga should have been encoded as Lo.
If the visarga (in Devanagari and all other Indic scripts) had been
given the category Lo, nothing would be lost. OTOH there is a gain that
first of all the semantics of the visarga sign (that it actually
represents an independent sound) is preserved, and stupidities like
making it a combining mark attaching to a digit are avoided. Rendering
engine makers will also easily cause the glyph of an Lo character to be
displayed without worrying about the previous character, so that the
given Sama Vedic text can be displayed properly without difficulties.
IMHO a character must be called a combining mark only if it can NEVER be
used independently. Barring strong evidence to support the surmise that
a given character can NEVER be used independently, like is the case of
most diacritics for the Latin script, or the Vedic accent signs, a
character should not blindly be encoded as Mc.
When a character has been attested as non-spacing or it is spacing but
is reordrant or enclosing, it automatically means that it cannot be used
separately from its base character. But in the case of characters which
are alleged to be spacing combining marks which are displayed in logical
order, the authorities should make all possible efforts to ensure that
it can never be separated from its base character before encoding it as Mc.
If the only issue here is preventing linebreaks before the visarga,
which is a valid need, I admit, I wish to point out as precedent point 3
of N3383, where the disallowing of linebreak is specified even while
labeling the symbols as Lo. The same can be done for the visarga.
So I strongly encourage the Unicode authorities to consider, if
possible, the changing of the visarga in the Indian scripts to Lo. If it
is not allowed under the stability principles, at least attach another
annotation to the visarga characters (at least in Devanagari) indicating
that sometimes the visarga needs to be placed after digits, so rendering
engine makers are advised of the need to allow for that.
I also provide a sample of the same Sama vedic text shown in Grantha
script which also shows the visarga coming after the digits.
On similar bases, the sign for the ardhavisarga proposed to be encoded
at 1CF2 should either receive a category change, if possible at this
stage of its Unicode proposal, or an annotation for this purpose. If at
all any jihvamuliya or upadhmaniya characters are proposed in the
future, they must be encoded as Lo, and not Mc, with linebreak being
prevented before them.
Again on a similar argument, the anusvara sign which also indicates a
separate phoneme in Sanskrit should also have been encoded as Lo and not
Mc, except in the cases of Devanagari (and any other script) where it is
non-spacing. See the sample provided from the Grantha script where the
anusvara is spacing and it is placed after a digit. Other samples can be
provided where it is placed after an avagraha too. So it should also be
ideally Lo in such scripts having a spacing anusvara, and if that is not
possible, annotations should be added for the purpose.
Shriramana Sharma

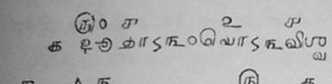
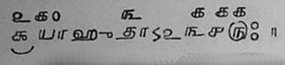
- Next message: Shriramana Sharma: "On adding svara marks to digits for the Rig Veda"
- Previous message: Danny Piccirillo: "Fwd: Copyleft Symbol"
- Next in thread: Shriramana Sharma: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Reply: Shriramana Sharma: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Reply: Peter Constable: "RE: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Maybe reply: Kenneth Whistler: "Re: Visarga, ardhavisarga and anusvara -- combining marks or not?"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Fri Aug 21 2009 - 07:37:16 CDT