Guidelines for Submitting Unicode® Emoji Proposals
Last Update: 2026-05-20
Currently Accepting Submissions Until 2026-07-31
The goal of this page is to outline the process and requirements for submitting a proposal for new emoji; including how to submit a proposal, the selection factors that need to be addressed in each proposal, and guidelines on presenting evidence of frequency.
All submissions are reviewed, and a very small percentage advance for encoding.
Documents submitted that are not publicly available, are incomplete, or from excluded categories are not eligible for consideration.
Note: If your proposal doesn’t meet the emoji criteria, but is a widely used symbol that doesn’t require color, follow the character proposal process outlined here.
Contents
A Submission consists of a proposal and example images. Please read this entire page and the linked pages before preparing a Submission.
Important Legal Notice
The Consortium licenses its standards openly and freely under various open-source licenses found here and here. Under these licenses, vendors implement encoded emoji into their products to be used all over the world. Therefore, once an emoji is encoded, it can never be removed. For this reason, the Consortium requires a broad perpetual license in any rights you or others may have in your proposed emoji.
So your first step in this process is to read the Emoji Proposal Agreement & License that you will be required to agree to as part of your Submission. This is an important legal agreement in which you (1) warrant that your proposed emoji is available for free and open licensing, and (2) grant to the Consortium broad rights, specifically a non-exclusive irrevocable, perpetual, worldwide, royalty-free license to encode your proposed emoji and to sublicense it under the Consortium’s various open-source licenses.
The Consortium cannot accept any submission that is not accompanied by this warranty and license from you.
Submissions reopened on April 2, 2026 and will close at the end of day on July 31, 2026.
Submissions will not be processed unless they are complete and adhere to these Guidelines. Some Submissions may be returned to the Submitter for modification based on Emoji Standard & Research Working Group review.
- Before preparing a document, ensure your proposal meets all of the requirements to be considered:
- See if it’s already been approved.
- Scan the list of Emoji Requests to see whether your proposed emoji has previously been submitted. Emoji that are listed as “Prioritization Pending” or “Under Consideration” do not require additional proposals. Emoji declined within the last four years are not eligible for re-review.
- Familiarize yourself with previous submission proposals. Don’t skip any of the fields in the form. The Emoji Standard & Research Working Group receives a lot of Submissions, and complete proposals help them best evaluate them.
- Read this entire document, including the Selection Factors.
- Read the Emoji Submission FAQ for common questions and their answers.
- Note that proposals will be automatically declined for logos, brands, other third-party IP rights, UI icons, signage, specific people, specific buildings and landmarks, deities, Region flags without ISO 3166 code, if it includes text, requests an exact image, proposes a variation on direction, or if you lack the required rights or license for images.
- Please do not justify the addition of an emoji because it furthers a “cause,” no matter how worthwhile. A proposal may be advanced despite a “cause” argument — if other factors are compelling — but will not be advanced because of it.
- Prepare your proposal document:
- Your document must contain all of the sections shown in the format below, provide empirical evidence, and address all of the questions specified there as completely as possible.
- Capture screenshots of usage frequency to include in your proposal to ensure it is relevant and meets all of the criteria.
- Note: Petitions, hashtags on social media, and anecdotal evidence are not acceptable data, and will not be considered.
- Create or procure open-source supporting example images of what the emoji would look like.
- Review your proposal document to confirm it is complete, has all of the necessary frequency citations, the images are not copyrighted, and meets all of the selection factors.
- Provide a link to your proposal document (PDF required) using the Unicode Emoji Submission Form.
- Note: Your PDF link needs to be publicly accessible. Email, FAX, or hard copies are not acceptable. Only documents sent via this Submission Form can be reviewed.
All submitters will be notified of the status of their document no later than November 30, 2026. Please keep in mind that many proposals are submitted and we are unable to respond to inquiries regarding the status of your proposal.
Title: Proposal for Emoji <name>
The <name> must describe the emoji being proposed, such as:
Proposal for Emoji: Smiling Face with Smiling Eyes and Hand Covering Mouth
Tips: Use a descriptive term, like “Smiling Face with Smiling Eyes and Hand Covering Mouth,” rather than something prescriptive, like “Laughing Face.”
Note: Proposed emoji names are subject to change by the Emoji Standard & Research Working Group and the Unicode Technical Committee.
Submitter: <name(s)>
The <name(s)> must clearly identify the Submitter(s). Use ; between multiple authors.
Note: One Author will need to be named as the main point of contact.
Date: <date>
When submitting revised proposals, the date must be updated.
- Identification. Suggested keywords for the emoji, as in the Emoji List.
- Keywords: Do not repeat the name of the emoji. Consider terms that people would use to find this emoji.
Example: If your emoji is “Smiling Face with Smiling Eyes and Hand Covering Mouth,” relevant keywords could include “laughing,” “cute,” “joyful,” “shy,” and “embarrassed.”
- Category: The proposed category for the emoji in Emoji Ordering.
Example: Smileys & Emotion face-smiling.
- Images: The format and license must be as specified in the Images section below.
- Color and black&white example images: Must be included at the top of the document in two sizes: 18×18 and 72×72 pixels. The small size of the images aids in illustrating if the image is distinctive enough at typical emoji sizes.
- License: As discussed further in the Images section below, the Submitter must certify that they own any and all IP Rights in the images, or if not, must identify where the images were obtained and certify that the images are public domain and/or are subject to appropriate open source licenses, thereby making the images suitable for incorporation into the Unicode Standard. Failure to include this information will result in a rejection of the proposal.
The above items must all be at the top of the first page.
- Factors for Inclusion. These factors support your proposal’s inclusion in the Unicode Standard. Address each and provide evidence (cite with data to back up any claims) to show that your emoji proposal:
- Expresses multiple concepts
- Can be used with other emoji to convey additional concepts
- Breaks new ground
- Is legible and visually distinctive
- Has a high usage level
- Frequency (provide evidence with numbers)
- Google Search
- Google Video Search
- Google Trends: Web Search
- Google Trends: Image Search
- Google Books Ngram Viewer
- Completes an incomplete category
- Is needed for compatibility with popular existing systems
For more information, see Factors for Inclusion below.
- Factors for Exclusion. These factors weigh against a proposal’s inclusion in the Unicode Standard. Address each and provide evidence (cite with data to back up any claims) to show that your emoji proposal is not:
- Already represented
- Overly specific
- Open-ended
- Transient
- Justified by an existing emoji
For more information, see Factors for Exclusion below.
- Other information. Any other information that would be helpful, such as design considerations for images.
Example color and black & white images must be included at the top of your proposal with dimensions of 18×18 and 72×72 pixels. Grayscale is not acceptable.
| ✅ color |
✅ black&white |
❌ grayscale |
 |
 |
 |
|
|
|
The Submitter must warrant that they own any and all IP Rights (as defined in the Emoji Proposal Agreement & License) in the Proposed Emoji, as Submitter’s own original work and/or by assignment and/or as a work for hire. This is required even if the image(s) has been developed by the Submitter with the assistance of AI tools.
If the Submitter does not own all IP Rights in the image(s) (either as their own work and/or by assignment and/or as a work for hire), then the Submitter must identify where the image(s) was obtained and warrant that the image(s) is public domain and/or is subject to one or more appropriate open source licenses, thereby making the image(s) suitable for incorporation into the Unicode Standard. Specifically, if Submitter does not own all IP Rights in the image(s), then Submitter must provide a URL to the image on a website where the required license or public domain designation for the image is clearly stated.
Example: https://en.wikipedia.org/wiki/Dachshund#/media/File:Short-haired-Dachshund.jpg
When you visit the above URL, the declared license is clearly stated as CC BY 3.0.
Failure to include this information will result in rejection of the proposal.
The goal of this section is to demonstrate the current and historical usage of your emoji proposal’s concept. You are expected to supply the following data to help the Emoji Standard & Research Working Group assess your proposal.
Please read this section and follow all the instructions; otherwise your proposal will likely be rejected.
- All data needs to be publicly available and reproducible. Of course, search results may vary over time, so the data you provide will be a snapshot at a particular time.
- You need to supply screenshots of each result for each of the methods listed: Google Search, Google Video Search, Google Trends (Web Search), Google Trends (Image Search), and Google Books Ngram Viewer.
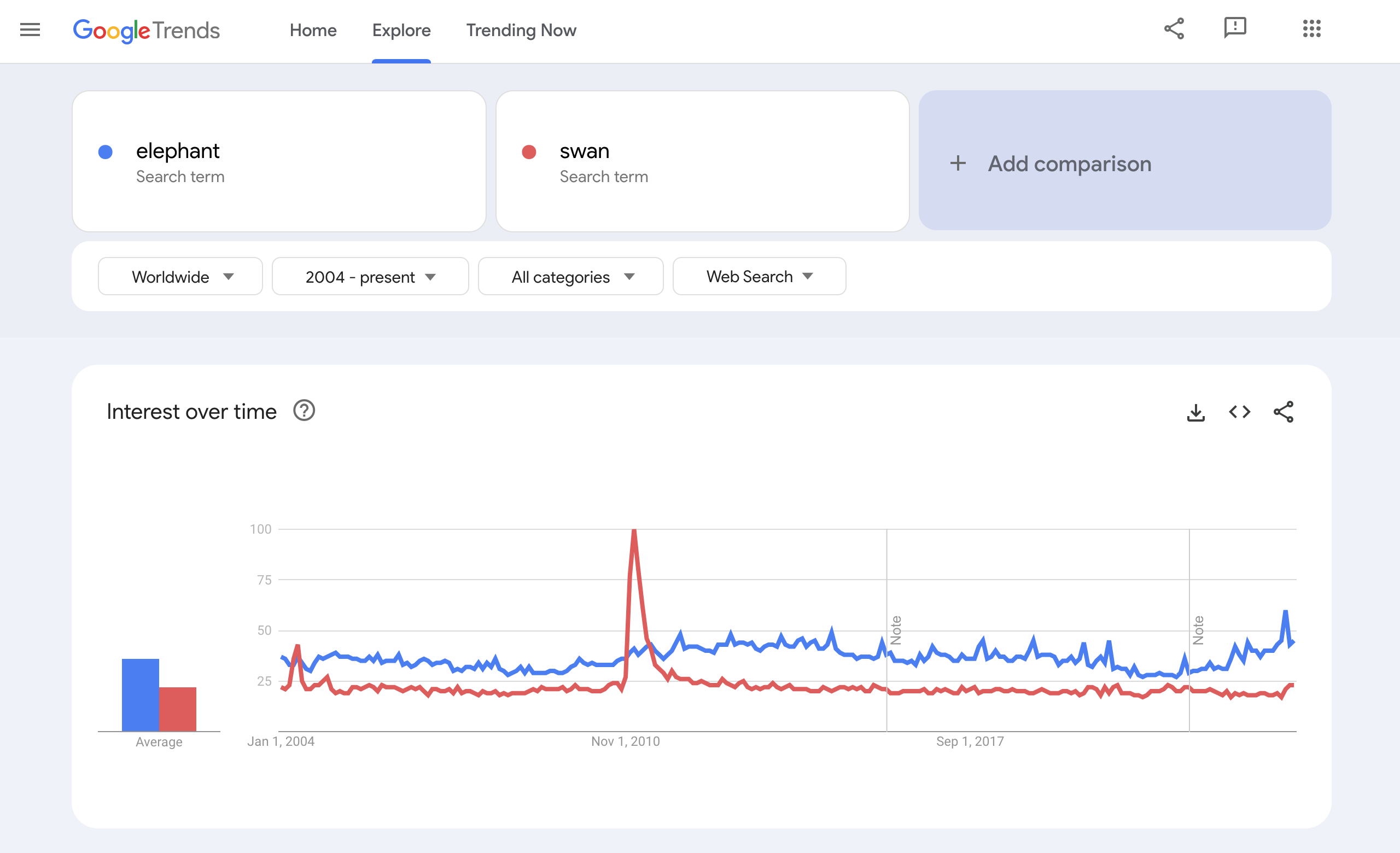
- Trends screenshots must include “elephant” as a comparative search term.
Note: If Google is not available in your location please utilize available search data to help establish usage levels. Please substantiate why your method is reproducible, and comparable in quality.
Tip: If you are submitting a facial-expression, be sure to provide search terms that describe how the image looks rather than what it means (for example, “smile with tears” rather than “proud face”). If you feel that there is a very strong association between your emoji and a more prescriptive phrase (for example, “happy tears”), you can include additional queries as supplemental evidence.
Petitions or “frequent requests” play no role in emoji encoding approval, and are not acceptable as evidence for citation.
- Do not include examples from social media of people calling for the emoji. That is not reliable enough data to be useful, and detracts from the strength of your proposal.
- Petitions are not considered as evidence since they are too easily skewed:
- Petitions may have duplicates or bot votes.
- The results could be skewed by commercial or special-interest promotions.
- The commercial petitions for 🌮 taco played no part in its selection; the taco was approved based on evidence in its proposal, not the petitions.
Some potential emoji names, like “seal,” could mean completely different things — for example, an animal or an adhesive? In some cases, the emoji can double as both meanings. But for others, it’s necessary to remove extraneous search results from your Frequency section, as best you can. In the following examples, a search phrase (what you would type in the search box) is presented in [square brackets].
- Minimize search personalization. Do all of your searches in a “private” browser window where possible, to help remove the effects of search personalization. Private browser windows are opened with menus like the following, depending on the browser: New Private Window, New Incognito Window, InPrivate Window
- Include a category term. When you search for [mammoth] alone, for example, you may get many irrelevant results, such as “Mammoth Mountain” (a ski resort) or “Mammoth Motocross” (a sports event).
- In these cases, add a term to provide focus to the results, such as [animal mammoth].
- Another example is “fly.” Because of the use as a verb (see below): [fly insect] can pick up items that are not about “flies” but rather other insects that fly.
- The category terms for each item don’t have to be identical, as long as they provide the appropriate filtering.
- For Google Trends, please also use a qualifying category.
- Group multiword terms. Use hyphens instead of spaces within a Google search. For example, when searching for black swan, use [black-swan]. Otherwise the search data you supply will likely be rejected (without the hyphen there could be a hit on a page with “black” in the first paragraph and “swan” in the last). For example, use:
- Choose your language. If your proposed emoji has high usage in a broad region of the world but relatively low usage in English, please also supply the equivalent searches in the appropriate language(s) of that region.
The information from the following sites is required. Include “elephant” as a comparative search term, and take a screenshot of each to include in your proposal.
- Google Search
- Google Video Search
- Google Trends: Web Search
- Google Trends: Image Search
- Google Books Ngram Viewer
Conduct a Google search, and include a screenshot with the number of results. Note you will need to click on the ‘Tools’ button, and the number will display on the far right side of the page.
https://www.google.com/search?q=elephant

Conduct a Google Video search, and include a screenshot with the number of results.
https://www.google.com/search?tbm=vid&q=swan

https://trends.google.com/trends/explore?date=all&q=elephant,swan
For this tool, you must also include a search for your proposed emoji and the term “elephant.”
For this and other tools that let you set start/end dates and locations, use the widest possible range.
Do the same as for Google Trends: Web Search, but pick Image Search.
https://trends.google.com/trends/explore?date=all_2008&gprop=images&q=elephant,swan
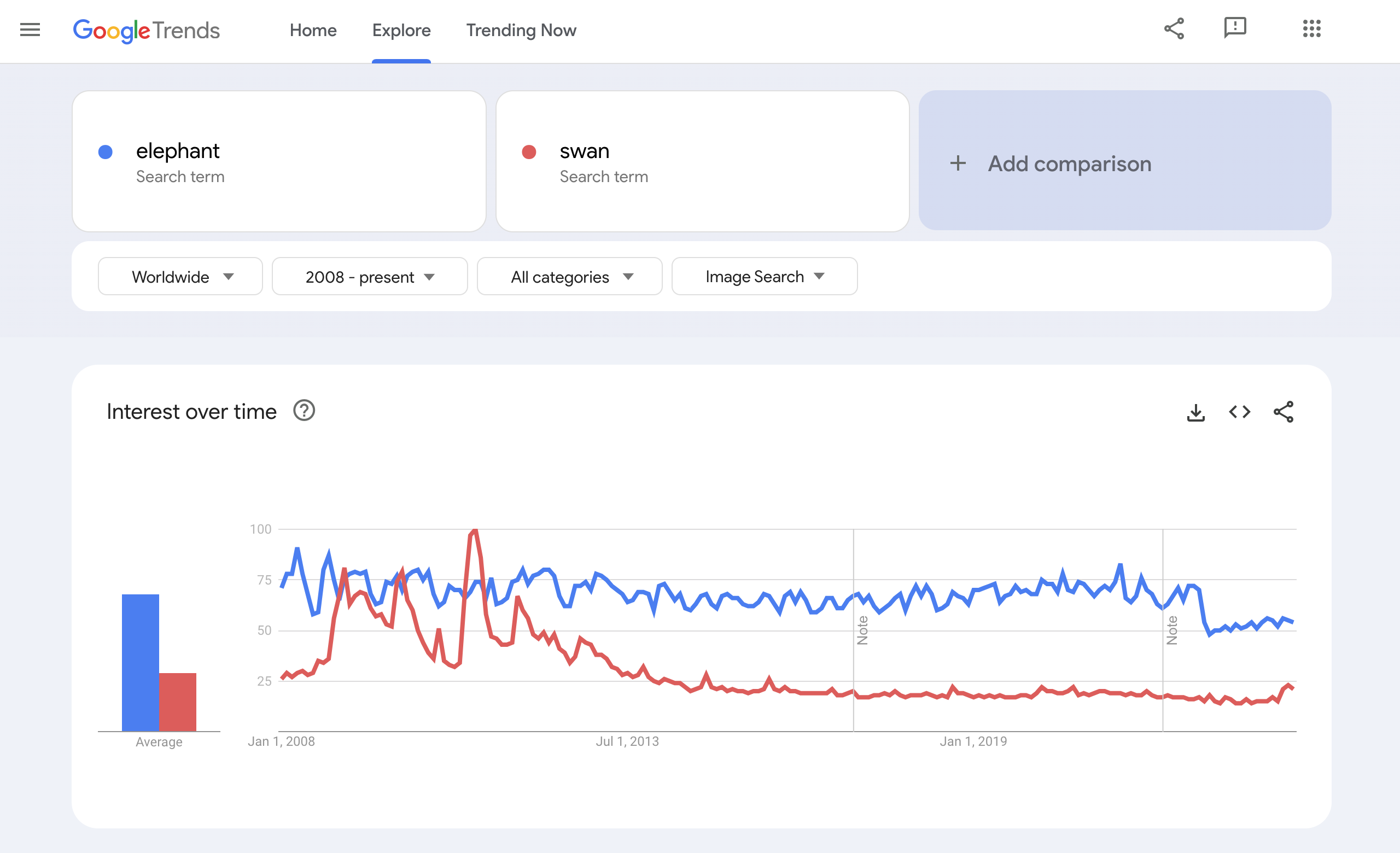
For this tool, you must also include a search for your proposed emoji and the term “elephant.”
For this and other tools that let you set start/end dates and locations, use the widest possible range.
https://books.google.com/ngrams/graph?content=elephant%2Cswan&year_start=1500&year_end=2019&corpus=en-2019&smoothing=3

Emoji proposals that have been accepted into the Unicode Standard can be found here.
As you read these, remember that new proposals must follow the current Format for Emoji Proposals. This format has changed substantially since earlier proposals were submitted.
There are two kinds of selection factors. Inclusion factors weigh in favor of encoding the emoji, and exclusion factors weigh against.
Unicode emoji characters were originally encoded on the basis of compatibility. Many emoji seem random or are specific to East Asia because the initial set originated from Japan. Examples include 🆕 new button and 🈯 Japanese “reserved” button.
Today, there are additional factors that the Emoji Standard & Research Working Group considers when assessing proposals. None of these factors alone determine eligibility or priority: all of the factors together are taken into consideration.
Note: Your proposal must include screenshots or citations to back up all claims.
- Multiple meanings: Does the emoji have notable metaphorical references or symbolism? This does not include puns.
- For example, archetype, metaphorical use, and symbolism may be supplied.
- 🦈 shark is not necessarily only the animal, but also used for a huckster, in jumping the shark, loan shark, and so on.
- 🐷 pig face may be used to evoke “hungry,” “zodiac sign,” “food,” or “farming.”
- 💪 flexed biceps are used to denote strength or simply “elbow.”
- Mark this as n/a unless there are compelling examples.
- Use in sequences: Can the emoji be used well in sequences?
- For example, 💦🧼👐 can convey handwashing, 😍😭 can indicate overwhelming cuteness, and 🗑️🔥 for garbage fire.
- Mark this as n/a unless there are compelling examples.
- Breaks new ground: Does the emoji represent something that is new and different?
- More weight is given to emoji that convey concepts that are not simply variants of concepts conveyed by existing emoji or sequences of existing emoji.
- Emoji are building blocks. Consider how this character represents a collection/group/family instead of a very specific breed or species.
- For example, because there is already an emoji for 🧹 broom, an emoji for vacuum cleaner would not break new ground
- Mark this as Yes or No. If Yes, explain why.
- Distinctiveness: Explain how and why your emoji represents a distinct, recognizable, visually iconic entity.
- Emoji images are paradigms, semantically representing a class of entities much larger than a specific image. Thus 🍺 beer mug represents not just a mug with exactly the shape you see on the screen, filled with beer of exactly that color, but rather beer in general.
- The term recognizable means most people should be able to discern that the representation is intended to depict a paradigm of that particular entity, without foreknowledge.
- The image you supply will not be used in products, but instead needs to demonstrate that the emoji is distinct enough to be recognizable at typical emoji sizes, such as 18×18 pixels on mobile phone screens.
- The term entity includes not only concrete objects, but also actions or emotions.
- Actions or activities may be represented by capturing a person or object in the midst of that action. Thus 🏃 person running also represents the action of running, and 😢 crying face also represents crying.
- Emotions or mental states can be represented by a face or body exhibiting that emotion or state. Thus 😠 angry face also represents being angry, or anger.
- A representation may use commonly understood “comic-style” visual elements, such as 💭 thought bubble, motion lines as in 👋 waving hand and 🗣 speaking head, or other signifiers such as in 😴 sleeping face.
- Usage level: Measures that can be presented as evidence include the following:
- Frequency: There should be high usage of the emoji term worldwide.
- Your proposal must include screenshots of searches for your emoji on the following platforms*:
- Google Search
- Google Video Search
- Google Trends: Web Search
- Google Trends: Image Search
- Google Books Ngram Viewer
- Note: petitions, hashtags on social media, and anecdotal evidence are not acceptable data, and will not be considered.
- *You may use other search engines that display real data only if Google is not available or accessible in your region.
- For more information, see Evidence of Frequency.
- Completeness: Does the proposed emoji fill a gap in existing types of emoji?
- In Unicode Version 8.0, for example, five emoji were added to complete the zodiac, including 🦂 scorpion.
- Other examples of fixed complete sets are blood types {🅰️🅱️🆎🅾️}, three wise monkeys {🙈🙉🙊}, and four card suits {♠️♣️♥️♦️}.
- Example: If the Unicode Standard included only three of the four card suits, proposing the fourth one would complete the set and require no future additions (see Open-ended below).
- The goal is iconic representation of large categories, not completeness in the sense of filling out the categories of a scientific or taxonomic classification system.
- Proposals should not attempt to make distinctions that are too narrow. For example, there is an emoji for 🎗️ reminder ribbon, and there is no need for finer gradations of color, such as purple ribbon.
- Example: There is already an emoji for 🐸 frog, which can be used to represent all amphibians.
- Mark this as n/a unless there are compelling examples.
- Compatibility: Are these needed for compatibility with popular existing systems, such as Snapchat, X, or QQ?
- Example: 🙄 face with rolling eyes was previously a popular emoticon on many web bulletin boards.
- For this to be a positive factor, the proposed emoji must also have evidence of high-frequency use in that existing system. Cite and provide screenshots for any claims made.
- Mark this as n/a unless there are compelling examples.
- Already representable: Can the concept be represented by another emoji or sequence, even if the image is not exactly the same?
- Examples:
- Handwashing can already be represented by 💦🧼👐 water droplets + soap + palms up together.
- Squirrel is already often represented by 🐿️ chipmunk.
- A building associated with a particular religion might be represented by 🛐 place of worship followed by a one of the many religious symbols in Unicode.
- Halloween could be represented by either just 🎃 jack-o-lantern, or a sequence of 🎃👻 jack-o-lantern + ghost.
- Overly specific: Is the proposed character overly specific?
- Example: 🍣 sushi represents sushi in general, although images frequently show a specific type, such as maguro. Adding saba, hamachi, sake, amaebi, and others would be overly specific.
- A limited number of emoji can be added each year. Thus, emoji that “break new ground” are strongly favored over emoji that are variants of others. Therefore, a proposal for additional species of owl would be viewed negatively.
- Open-ended: Is it just one of many, with no special reason to favor it over others of that type?
- If this emoji is added, will it result in the need to add other similar types? The addition of one emoji is the exclusion of another.
- Example: There is a large and ever-growing number of dog breeds or flavors of beer that exist, so adding individual specific breeds or flavors would favor one over any other.
- Transient: Is the expected level of usage likely to continue into the future, or could it just be a fad?
- Transient or faddish symbols are poor candidates for encoding.
- Faulty comparison: Are proposals being justified primarily by being similar to (or more important than) existing emoji?
- An existing emoji’s existence does not justify proposals for emoji like them.
- Examples:
- Four different mailboxes {📫📪📬📭} do not justify adding a “more important than a mailbox” emoji.
- 🆕 new button does not justify adding an emoji for “OLD,” or an emoji for “NEU” (German). The same is true of ideographic emoji, such as 🈯 Japanese “reserved” button.
- The emoji {🐶🐕} do not justify additional front versus full-body views of the same animal.
- The emoji {🐕🐩} or {🐪🐫} do not justify adding different varieties of the same kind of animal.
- The Tokyo Tower🗼(a specific building) does not justify adding the Eiffel Tower.
- Many historical emoji violate current factors for inclusion. Once an emoji is encoded it cannot be removed from the Unicode Standard.
- As new emoji have been added to the Unicode Standard many emoji categories are reaching or are at a point of saturation. As a result — and upon reflecting on how emoji are used — the Unicode Consortium approves fewer and fewer emoji proposals every year.
- More information on how the Unicode Consortium considers new additions to the standard can be found here.
- Logos, brands, other third-party IP rights, UI icons, signage, specific people, specific buildings and landmarks, deities: The following are images unsuitable for encoding as characters.
- Images such as company logos, or those showing company brands as part or all of the image, or images of products strongly associated with a particular brand.
- Images or designs in which third-parties may have rights to, such as images from non-public domain artwork, movies, books, and so on.
- UI icons such as Material Design Icons, Winjs Icons, or Font Awesome Icons, which are often discarded or modified to meet evolving UI needs.
- Signage such as
 . See also Slate’s The Big Red Word vs. the Little Green Man.
. See also Slate’s The Big Red Word vs. the Little Green Man.
- Note: symbols used in signage or user interfaces may be encoded in Unicode for reasons unconnected with their use as emoji.
- Specific people, whether fictional, historic, living, or dead.
- Specific buildings, structures, landmarks, or other locations, whether fictional, historic, or modern.
- Deities.
- Flags: The Unicode Consortium will no longer accept proposals for flags. Flags that correspond to officially assigned ISO 3166-1 alpha-2 region codes are automatically added, with no proposals necessary.
- Lack of required rights or license for images: Lack of required rights or license for images, or public domain status for the images will be automatically declined.
- Exact images: Does the proposal request an exact image? Emoji may display differently depending on the platform and design of the emoji font in use.
- Includes text: We no longer encode emoji that include text because they pose localization challenges, and may not be internationally recognizable.
- Variations on direction: Proposals to add directional variation (for example, a skier skiing the other direction) are not eligible for consideration at this time.
