Indic Scripts and Languages
Q: What are Indic scripts?
Indic scripts in the narrow sense are the nine major Brahmi-derived scripts of India. In a wider sense, the term can cover all Brahmic scripts and Kharoshthi. For example, the file IndicSyllabicCategory.txt in the Unicode Character Database contains data on Brahmi and Brahmi-derived scripts in the wider sense. Sometimes, you may also hear the term Neo-Brahmi. When the Unicode Standard refers to "Indic scripts" it uses the term in the wider sense.
There is not a one-to-one relation between Indic scripts and languages. Scripts are typically used to write multiple languages, and many languages are written in multiple scripts. Unicode encodes characters based on scripts.
Q: How do the Indic scripts work in Unicode?
See Chapter 12, South and Central Asian Scripts-I in The Unicode Standard.
Particularly relevant is the section on Devanagari, which is a detailed description not only of the Devanagari script but also outlines the model used for all similarly structured scripts in the standard. This model is the based on the ISCII model and requires a coordination between layout engines and fonts.
Information about the OpenType and Uniscribe formats can be found in the excellent article Windows Glyph Processing by John Hudson. [AJ]
by John Hudson. [AJ]
Q: What is ISCII?
Indian Standard Code for Information Interchange (ISCII) is the character code for Indian scripts that originate from the Brahmi script. ISCII was evolved by a standardization committee under the Department of Electronics during 1986-88, and adopted by the Bureau of Indian Standards (BIS) in 1991. Unlike Unicode, ISCII is an 8-bit encoding that uses escape sequences to announce the particular Indic script represented by a following coded character sequence. The ISCII document is IS13194:1991, available from the BIS offices.
Q: How does Unicode differ from ISCII?
Except for a few minor differences, each script encoded in ISCII corresponds directly to a block range in Unicode. However, having been designed as a multilingual encoding, Unicode needs no escape sequences or switching between scripts. For any given Indic script, the consonant and vowel letter codes of Unicode are based on ISCII. ISCII allowed control over character formation by combining letters with the characters NUKTA, INV, and HALANT. Unicode provides similar control with the ZWJ and ZWNJ characters.
The prototypical example is the "explicit halant":
| ISCII: | Halant + Halant |
|---|---|
| Unicode: | Halant + ZWNJ |
The "soft halant" of ISCII is expressed:
| ISCII: | Halant + Nukta |
|---|---|
| Unicode: | Halant + ZWJ |
The "explicit halant" is discussed in the ISCII standard, section 6.3.1 and "soft halant" is discussed in 6.3.2.
There are several categories of such differences. See also Chapter 12, South and Central Asian Scripts-I in The Unicode Standard for details. Unicode also includes the right side "pieces" of some two-part vowel signs for compatibility with some software.
The ISCII Attribute code (ATR) is not represented in the Unicode Standard, which is a plain text standard. The ISCII Attribute code is intended to explicitly define a font attribute applicable to following characters, and thus represents an embedded control for the kinds of font and style information which is not carried in a plain text encoding.
The ISCII Extension code (EXT) is also not represented directly in the Unicode Standard. The Extension code is an escape mechanism, allowing the 8-bit ISCII standard to define an extended repertoire via an escaped reencoding of certain byte values. Such a mechanism is not required in the Unicode Standard, which simply uses additional code points to encode any additional character repertoire.
Q: How does the use of nukta differ in Unicode?
There are four uses of nukta in ISCII. Unicode doesn't use nukta for soft halant and also doesn't use it for code extension. However, Unicode does use nukta to represent the nukta diacritic either in cases such as "ka" U+0958 or cases like "nnna" U+0929. Unicode doesn't use nukta for the "om" character (eg. candrabindu + nukta in ISCII, which is encoded as a separate character in Unicode).
Q: What are the Unicode equivalents for combinations that use the "invisible letter" (INV) in ISCII?
When the INV is used in ISCII as a base letter, this may be expressed with a space or no-break space in Unicode. The choice depends on whether it is used as a "word-like" character or not:
| ISCII | Unicode |
|---|---|
| INV + vowel-sign | SPACE + vowel-sign |
| INV + vowel-sign | NBSP + vowel-sign |
Q: Is India involved in Unicode?
The Government of India has participated as a member of the Unicode Consortium for over two decades, and has been engaged in a dialogue with the UTC about additional characters in the Indic scripts and improvements to the textual descriptions and annotations.
Q: How does Unicode cover Vedic accents?
Characters used to indicate tone in Vedic Sanskrit appear in the Devanagari Extended block, the Vedic Extensions block, and the Devanagari block. A brief overview is given in the Devanagari Extended and Vedic Extensions block introductions in Chapter 12, South and Central Asian Scripts-I in The Unicode Standard.
Q: What is the difference between Unicode fonts and other fonts?
See the Font FAQ for a general description of "What is a Unicode Font". The font would need to contain a glyph for each allocated code point of the script. For example, Gujarati would contain glyphs for the allocated code points in the range: U+0A80 - U+0AFF. In addition to these, the font should have:
- (a) glyphs for conjuncts;
- (b) variants for vowel signs (matras), vowel modifiers (candrabindu, anusvara), the consonant modifier (nukta);
- (c) digits and any appropriate punctuation marks, including some from the Latin ranges.
The contents of (a) and (b) depend not only on the typographical quality the font is intended to achieve but also whether the font is limited to contemporary use or also includes glyphs used in traditional formats.
The contents of (a) and (b) can be implemented by providing a Glyph Substitution table in the font. Such a table is more often than not a necessity for Indic scripts. A Glyph Positioning table is also needed for achieving the minimal required mark positioning in such scripts. More information on these issues is contained in the OpenType Specification.
There is also a specification for Developing OpenType Fonts for the Devanagari Script, as well as the other Indic scripts. [AJ]
Q:Where can I find Unicode fonts for Indic scripts?
Google has created a series of Noto fonts covering the Indic Scripts. They are available for download.
Microsoft has made several OpenType Indic script fonts:
Nirmala UI (all Indic scripts)
Latha - Tamil
Mangal (Devanagari)
Raavi (Gurmukhi and Devanagari)
Shruti (Gujarati and Devanagari)
Tunga (Kannada and Devanagari)
Microsoft Windows supplies a number of fonts for Indic scripts. They are listed in the Windows 11 Font List. Information for earlier versions can be accessed from there.
The Indic fonts shipped with Apple's products support Indic scripts using the Unicode encoding.
There are also many other small development teams creating Indic fonts. Many of them are listed on Alan Wood's Unicode Fonts page.
Q: Do I need an IME to properly input Indic script languages?
Indic languages can be input via a traditional keyboard, with a proper keyboard mapping. The work then falls to the rendering engine to display the characters in their proper order and shape.[CW]
Q: Is the keyboard arrangement in a Unicode system different from that of the regular "TTF" fonts?
Keyboarding questions are separate from the questions of encoding. Some of the keyboards provided with Windows can been seen on Microsoft's Windows Keyboard Layout website. [AJ]
Q: Where can I find information about Tamil?
See the Tamil FAQ.
Q: Where can I find information about Bengali (Bangla) or Assamese?
See the Bengali (Bangla) / Assamese Script FAQ.
Q: How do I collate Indic language data?
Collation order is not the same as code point order. A good treatment of some issues specific to collation in Indic languages can be found in the paper Issues in Indic Language Collation by Cathy Wissink.
Collation in general must proceed at the level of language or language variant, not at the script or code point levels. See also UTS #10, Unicode Collation Algorithm. Some Indic-specific issues are also discussed in that report.
Q: Where can I find the "half forms" of Devanagari letters (or any other Indic script) in the Unicode code charts?
Half forms are needed to form words such as "patni". Unicode does not directly encode half or subjoined letters for the scripts of India. Like in the ISCII standard, Unicode forms all "consonant clusters" (such as the "tn" in "patni") by inserting the character virama (or halant) between the two relevant consonant letters. For instance, the Devanagari syllable "tna" ("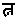 ") is encoded with the following code points:
") is encoded with the following code points:
| U+0924 | त | DEVANAGARI LETTER TA |
| U+094D | ◌् | DEVANAGARI SIGN VIRAMA (= halant) |
| U+0928 | न | DEVANAGARI LETTER NA |
These three characters will sometimes be displayed using the single glyph tna ligature "". But it is also possible that they are displayed using a half ta glyph followed by a full na glyph "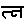 ".
".
Which form will be actually displayed is the decision of an underlying software module called a "display engine", which bases this decision on the availability of glyphs in the font.
If the sequence <U+0924, U+094D> is not followed by another consonant letter (such as "na") it is always displayed as a full ta glyph combined with the virama glyph "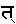 ".
".
Unicode provides a way to force the display engine to show a half letter form. To do this, an invisible character called ZERO WIDTH JOINER should be inserted after the virama:
| U+0924 | त | DEVANAGARI LETTER TA |
| U+094D | ◌् | DEVANAGARI SIGN VIRAMA (= halant) |
| U+200D | ZERO WIDTH JOINER | |
| U+0928 | न | DEVANAGARI LETTER NA |
This sequence is always displayed as a half ta glyph followed by a full na glyph "". Even if the consonant "na" is not present, the sequence <U+0924, U+094D, U+200D> is displayed as a half ta glyph "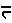 ".
".
Unicode also provides a way to force the display engine to show the virama glyph. To do this, an invisible character called ZERO WIDTH NON-JOINER should be inserted after the virama:
| U+0924 | त | DEVANAGARI LETTER TA |
| U+094D | ◌् | DEVANAGARI SIGN VIRAMA (= halant) |
| U+200C | ZERO WIDTH NON-JOINER | |
| U+0928 | न | DEVANAGARI LETTER NA |
This sequence is always displayed as a full ta glyph combined with a virama glyph and followed by a full na glyph " "
"
For more detailed information, see Chapter 12, South and Central Asian Scripts-I in The Unicode Standard. For related issues, see "Where is My Character?"[MC]
Q: Can you rename the character called VIRAMA in my script to HALANT?
In the Unicode Standard, the sign indicating the absence of an inherent vowel in Indic scripts is denoted by the Sanskrit word virama. In the particular languages another designation is often preferred. In Hindi, for example, the word hal refers to the character itself, and halant refers to the consonant that has its inherent vowel suppressed; in Tamil, the word pulli is used; in Bangla, the word hasant is used, and so on.
The Unicode stability policies prevent character names from being changed. However, the code charts and character descriptions often contain annotations showing the preferred name, such as:
| 094D DEVANAGARI SIGN VIRAMA | |
| = halant (the preferred Hindi name) | |
| • suppresses inherent vowel | |
Q: Why do KANNADA VOWEL SIGN I (U+0CBF) and KANNADA VOWEL SIGN E (U+0CC6) seem to have inconsistent character properties?.
These vowel signs have General Category Nonspacing_Mark (Mn) and Bidi_Class Left (L) even though UAX #9 says that all Mn category characters are Bidi_Class Nonspacing_Mark (NSM). This was an explicit decision by UTC for these characters, to preserve canonical equivalence under the Unicode Bidirectional Algorithm (UBA) for two vowels involving these as parts of decompositions.
The UBA is designed to maintain canonical equivalence. Normally all of the combining characters have the Bidi_Class NSM, but when combining characters would cause problems, that value may be changed to a value which helps to maintain canonical equivalence.
Q: How are the Sindhi implosives represented?
The characters U+097B DEVANAGARI LETTER GGA, U+097C DEVANAGARI LETTER JJA, U+097E DEVANAGARI LETTER DDDA, and U+097F DEVANAGARI LETTER BBA are used to write Sindhi implosive consonants. Versions of the Unicode Standard prior to Version 5.0 recommended the representation of Sindhi implosive consonants by sequences of the plain consonant letters followed by anudatta (or by nukta). Such sequences are no longer recommended. [EM]